Zippers

Embora a pureza do Haskell traga um monte de benefícios, ela nos faz abordar alguns problemas de forma diferente do que faríamos em linguagens impuras. Por causa da transparência referencial, um valor é tão bom quanto outro no Haskell se representar a mesma coisa.
Então, se tivermos uma árvore cheia de cincos (high-fives, talvez?) e quisermos mudar um deles para um seis, temos que ter alguma maneira de saber exatamente qual cinco em nossa árvore queremos mudar. Temos que saber onde ele está na nossa árvore. Em linguagens impuras, poderíamos apenas notar onde na nossa memória o cinco está localizado e mudá-lo. Mas no Haskell, um cinco é tão bom quanto outro, então não podemos discriminar com base em onde eles estão na nossa memória. Também não podemos realmente mudar nada; quando dizemos que mudamos uma árvore, na verdade queremos dizer que pegamos uma árvore e retornamos uma nova que é semelhante à árvore original, mas ligeiramente diferente.
Uma coisa que podemos fazer é lembrar um caminho da raiz da árvore até o elemento que queremos mudar. Poderíamos dizer: pegue esta árvore, vá para a esquerda, vá para a direita e depois para a esquerda novamente e mude o elemento que está lá. Embora isso funcione, pode ser ineficiente. Se quisermos mudar mais tarde um elemento que esteja perto do elemento que mudamos anteriormente, temos que percorrer todo o caminho desde a raiz da árvore até o nosso elemento novamente!
Neste capítulo, veremos como podemos pegar alguma estrutura de dados e focar em uma parte dela de uma maneira que torne a mudança de seus elementos fácil e o caminhar por ela eficiente. Legal!
Dando um passeio
Como aprendemos na aula de biologia, existem muitos tipos diferentes de árvores, então vamos escolher uma semente que usaremos para plantar a nossa. Aqui está:
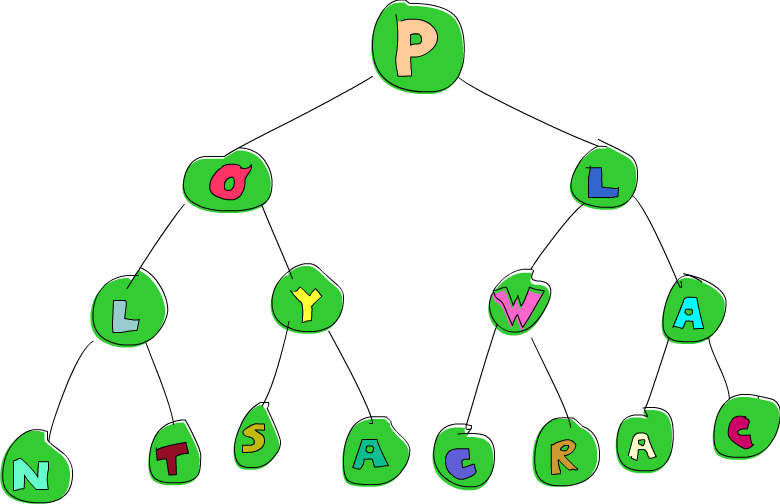
data Tree a = Empty | Node a (Tree a) (Tree a) deriving (Show)Então a nossa árvore ou está vazia ou é um nó que tem um elemento e duas subárvores. Aqui está um belo exemplo de tal árvore, que eu dou a você, leitor, de graça!
freeTree :: Tree Char
freeTree =
Node 'P'
(Node 'O'
(Node 'L'
(Node 'N' Empty Empty)
(Node 'T' Empty Empty)
)
(Node 'Y'
(Node 'S' Empty Empty)
(Node 'A' Empty Empty)
)
)
(Node 'L'
(Node 'W'
(Node 'C' Empty Empty)
(Node 'R' Empty Empty)
)
(Node 'A'
(Node 'A' Empty Empty)
(Node 'C' Empty Empty)
)
)E aqui está esta árvore representada graficamente:
Notou aquele W na árvore ali? Digamos que queiramos
mudá-lo para um P. Como faríamos isso? Bem, uma maneira
seria fazer pattern matching na nossa árvore até encontrarmos o elemento
localizado indo primeiro para a direita e depois para a esquerda e
mudando o dito elemento. Aqui está o código para isso:
changeToP :: Tree Char -> Tree Char
changeToP (Node x l (Node y (Node _ m n) r)) = Node x l (Node y (Node 'P' m n) r)Eca! Não só isso é bastante feio, como também é meio confuso. O que
acontece aqui? Bem, fazemos pattern matching na nossa árvore e nomeamos
seu elemento raiz como x (que se torna o 'P'
na raiz) e sua subárvore esquerda como l. Em vez de dar um
nome à sua subárvore direita, fazemos mais pattern matching nela.
Continuamos este pattern matching até chegarmos à subárvore cuja raiz é
o nosso 'W'. Uma vez feito isso, reconstruímos a árvore, só
que a subárvore que continha o 'W' na sua raiz agora tem um
'P'.
Existe uma maneira melhor de fazer isso? Que tal fazermos nossa
função receber uma árvore junto com uma lista de direções. As direções
serão L ou R, representando esquerda (left) e
direita (right) respectivamente, e mudaremos o elemento em que chegarmos
se seguirmos as direções fornecidas. Aqui está:
data Direction = L | R deriving (Show)
type Directions = [Direction]
changeToP :: Directions -> Tree Char -> Tree Char
changeToP (L:ds) (Node x l r) = Node x (changeToP ds l) r
changeToP (R:ds) (Node x l r) = Node x l (changeToP ds r)
changeToP [] (Node _ l r) = Node 'P' l rSe o primeiro elemento na nossa lista de direções for L,
construímos uma nova árvore que é como a árvore antiga, só que sua
subárvore esquerda tem um elemento alterado para 'P'.
Quando chamamos recursivamente changeToP, passamos apenas o
resto da lista de direções, porque já fomos para a esquerda. Fazemos a
mesma coisa no caso de um R. Se a lista de direções estiver
vazia, isso significa que estamos no nosso destino, então retornamos uma
árvore que é como a fornecida, só que tem 'P' como seu
elemento raiz.
Para evitar imprimir a árvore toda, vamos fazer uma função que receba uma lista de direções e nos diga qual é o elemento no destino:
elemAt :: Directions -> Tree a -> a
elemAt (L:ds) (Node _ l _) = elemAt ds l
elemAt (R:ds) (Node _ _ r) = elemAt ds r
elemAt [] (Node x _ _) = xEsta função é na verdade bastante semelhante à
changeToP, só que em vez de lembrar as coisas ao longo do
caminho e reconstruir a árvore, ela ignora tudo exceto seu destino. Aqui
mudamos o 'W' para um 'P' e vemos se a mudança
na nossa nova árvore permanece:
ghci> let newTree = changeToP [R,L] freeTree
ghci> elemAt [R,L] newTree
'P'Legal, isso parece funcionar. Nestas funções, a lista de direções
atua como uma espécie de foco, porque aponta para uma subárvore
exata da nossa árvore. Uma lista de direções [R] foca na
subárvore que está à direita da raiz, por exemplo. Uma lista de direções
vazia foca na árvore principal em si.
Embora esta técnica possa parecer legal, ela pode ser bastante ineficiente, especialmente se quisermos mudar elementos repetidamente. Digamos que temos uma árvore realmente enorme e uma longa lista de direções que aponta para algum elemento lá no fundo da árvore. Usamos a lista de direções para dar um passeio pela árvore e mudar um elemento no fundo. Se quisermos mudar outro elemento que esteja perto do elemento que acabamos de mudar, temos que começar pela raiz da árvore e percorrer todo o caminho até ao fundo novamente! Que chato.
Na próxima seção, encontraremos uma maneira melhor de focar em uma subárvore, uma que nos permita mudar o foco eficientemente para subárvores que estejam próximas.
Um rastro de migalhas

Certo, então para focar em uma subárvore, queremos algo melhor do que apenas uma lista de direções que sempre seguimos a partir da raiz da nossa árvore. Ajudaria se começássemos na raiz da árvore e nos movêssemos um passo de cada vez para a esquerda ou para a direita e deixássemos uma espécie de rastro de migalhas? Ou seja, quando vamos para a esquerda, lembramos que fomos para a esquerda e quando vamos para a direita, lembramos que fomos para a direita. Com certeza, podemos tentar isso.
Para representar nossas migalhas de pão, também usaremos uma lista de
Direction (que é L ou R), só que
em vez de chamá-la de Directions, vamos chamá-la de
Breadcrumbs (migalhas), porque as nossas direções agora
estarão invertidas, já que as estamos deixando à medida que descemos
pela nossa árvore:
type Breadcrumbs = [Direction]Aqui está uma função que recebe uma árvore e algumas migalhas e se
move para a subárvore esquerda enquanto adiciona L ao
início da lista que representa nossas migalhas:
goLeft :: (Tree a, Breadcrumbs) -> (Tree a, Breadcrumbs)
goLeft (Node _ l _, bs) = (l, L:bs)Ignoramos o elemento na raiz e a subárvore direita e apenas
retornamos a subárvore esquerda junto com as migalhas antigas com
L no início. Aqui está uma função para ir para a
direita:
goRight :: (Tree a, Breadcrumbs) -> (Tree a, Breadcrumbs)
goRight (Node _ _ r, bs) = (r, R:bs)Ela funciona da mesma maneira. Vamos usar essas funções para pegar a
nossa freeTree e ir para a direita e depois para a
esquerda:
ghci> goLeft (goRight (freeTree, []))
(Node 'W' (Node 'C' Empty Empty) (Node 'R' Empty Empty),[L,R])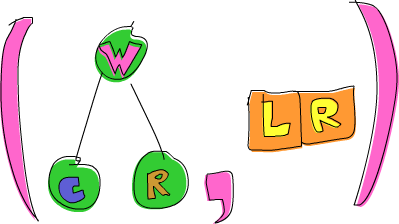
Certo, então agora temos uma árvore que tem 'W' na sua
raiz e 'C' na raiz da sua subárvore esquerda e
'R' na raiz da sua subárvore direita. As migalhas são
[L,R], porque primeiro fomos para a direita e depois para a
esquerda.
Para tornar o caminhar pela nossa árvore mais claro, podemos usar a
função -: que definimos assim:
x -: f = f xO que nos permite aplicar funções a valores escrevendo primeiro o
valor, depois um -: e então a função. Então, em vez de
goRight (freeTree, []), podemos escrever
(freeTree, []) -: goRight. Usando isso, podemos reescrever
o exemplo acima para que fique mais aparente que primeiro estamos indo
para a direita e depois para a esquerda:
ghci> (freeTree, []) -: goRight -: goLeft
(Node 'W' (Node 'C' Empty Empty) (Node 'R' Empty Empty),[L,R])Voltando para cima
E se quisermos agora voltar para cima na nossa árvore? Pelas nossas migalhas de pão, sabemos que a árvore atual é a subárvore esquerda do seu pai e que ela é a subárvore direita do seu pai, mas é só isso. Elas não nos contam o suficiente sobre o pai da subárvore atual para podermos subir na árvore. Parece que, além da direção que tomamos, uma única migalha deveria conter também todos os outros dados necessários para voltarmos. Neste caso, esse dado é o elemento na árvore pai junto com a sua subárvore direita.
Em geral, uma única migalha de pão deve conter todos os dados necessários para reconstruir o nó pai. Portanto, deve ter a informação de todos os caminhos que não tomamos e também deve saber a direção que tomamos, mas não deve conter a subárvore em que estamos focando atualmente. Isso ocorre porque já temos essa subárvore no primeiro componente da tupla, então se a tivéssemos também nas migalhas, teríamos informação duplicada.
Vamos modificar as nossas migalhas para que elas também contenham
informações sobre tudo o que ignoramos anteriormente ao nos movermos
para a esquerda e para a direita. Em vez de Direction,
criaremos um novo tipo de dado:
data Crumb a = LeftCrumb a (Tree a) | RightCrumb a (Tree a) deriving (Show)Agora, em vez de apenas L, temos um
LeftCrumb que também contém o elemento no nó do qual nos
movemos e a árvore direita que não visitamos. Em vez de R,
temos RightCrumb, que contém o elemento no nó do qual nos
movemos e a árvore esquerda que não visitamos.
Estas migalhas agora contêm todos os dados necessários para recriar a árvore pela qual caminhamos. Portanto, em vez de serem apenas migalhas de pão normais, agora elas são mais como disquetes que deixamos à medida que avançamos, porque contêm muito mais informação do que apenas a direção que tomamos.
Em essência, cada migalha de pão agora é como um nó de árvore com um
buraco. Quando nos movemos para mais fundo na árvore, a migalha carrega
toda a informação que o nó do qual nos distanciamos carregava,
exceto a subárvore na qual escolhemos focar. Ela também tem que
notar onde está o buraco. No caso de um LeftCrumb, sabemos
que nos movemos para a esquerda, então a subárvore que falta é a da
esquerda.
Vamos também mudar o nosso sinônimo de tipo Breadcrumbs
para refletir isso:
type Breadcrumbs a = [Crumb a]Em seguida, temos que modificar as funções goLeft e
goRight para armazenar informações sobre os caminhos que
não tomamos nas nossas migalhas de pão, em vez de ignorar essa
informação como faziam antes. Aqui está a goLeft:
goLeft :: (Tree a, Breadcrumbs a) -> (Tree a, Breadcrumbs a)
goLeft (Node x l r, bs) = (l, LeftCrumb x r:bs)Você pode ver que ela é muito semelhante à nossa goLeft
anterior, só que em vez de apenas adicionar um L ao início
da nossa lista de migalhas, adicionamos um LeftCrumb para
significar que fomos para a esquerda e equipamos o nosso
LeftCrumb com o elemento no nó do qual nos movemos (que é o
x) e a subárvore direita que escolhemos não visitar.
Observe que esta função assume que a árvore atual sob foco não é
Empty. Uma árvore vazia não tem subárvores, então se
tentarmos ir para a esquerda a partir de uma árvore vazia, ocorrerá um
erro porque o pattern match em Node não terá sucesso e não
há nenhum padrão que cuide de Empty.
A goRight é semelhante:
goRight :: (Tree a, Breadcrumbs a) -> (Tree a, Breadcrumbs a)
goRight (Node x l r, bs) = (r, RightCrumb x l:bs)Anteriormente fomos capazes de ir para a esquerda e para a direita. O
que conseguimos agora é a habilidade de realmente voltar para cima
lembrando coisas sobre os nós pais e os caminhos que não visitamos. Aqui
está a função goUp:
goUp :: (Tree a, Breadcrumbs a) -> (Tree a, Breadcrumbs a)
goUp (t, LeftCrumb x r:bs) = (Node x t r, bs)
goUp (t, RightCrumb x l:bs) = (Node x l t, bs)
Estamos focando na árvore t e verificamos qual é a
última Crumb. Se for uma LeftCrumb, então
construímos uma nova árvore onde a nossa árvore t é a
subárvore esquerda e usamos a informação sobre a subárvore direita que
não visitamos e o elemento para preencher o resto do Node.
Como voltamos, por assim dizer, e pegamos a última migalha para recriar
com ela a árvore pai, a nova lista de migalhas não a contém.
Observe que esta função causa um erro se já estivermos no topo de uma árvore e quisermos subir.
Mais tarde, usaremos a Maybe Monad para representar possíveis falhas ao mover o foco.
Com um par de Tree a e Breadcrumbs a, temos
todas as informações para reconstruir a árvore inteira e também temos um
foco em uma subárvore. Este esquema também nos permite mover facilmente
para cima, para a esquerda e para a direita. Tal par que contém uma
parte focada de uma estrutura de dados e seus arredores é chamado de
zipper, porque mover o nosso foco para cima e para
baixo na estrutura de dados assemelha-se à operação de um zíper em uma
calça comum. Portanto, é legal criarmos um sinônimo de tipo como
este:
type Zipper a = (Tree a, Breadcrumbs a)Eu preferiria nomear o sinônimo de tipo como Focus,
porque isso deixaria mais claro que estamos focando em uma parte de uma
estrutura de dados, mas o termo zipper é mais amplamente
utilizado para descrever tal configuração, então ficaremos com
Zipper.
Manipulando árvores sob foco
Agora que podemos nos mover para cima e para baixo, vamos fazer uma função que modifique o elemento na raiz da subárvore em que o zipper está focando:
modify :: (a -> a) -> Zipper a -> Zipper a
modify f (Node x l r, bs) = (Node (f x) l r, bs)
modify f (Empty, bs) = (Empty, bs)Se estivermos focando em um nó, modificamos seu elemento raiz com a
função f. Se estivermos focando em uma árvore vazia,
deixamos como está. Agora podemos começar com uma árvore, mover-nos para
onde quisermos e modificar um elemento, tudo isso mantendo o foco nesse
elemento para que possamos facilmente nos mover mais para cima ou para
baixo. Um exemplo:
ghci> let newFocus = modify (\_ -> 'P') (goRight (goLeft (freeTree,[])))Vamos para a esquerda, depois para a direita e então modificamos o
elemento raiz substituindo-o por um 'P'. Isso fica ainda
melhor se usarmos -::
ghci> let newFocus = (freeTree,[]) -: goLeft -: goRight -: modify (\_ -> 'P')Podemos então subir se quisermos e substituir um elemento por um
misterioso 'X':
ghci> let newFocus2 = modify (\_ -> 'X') (goUp newFocus)Ou se escrevêssemos com -::
ghci> let newFocus2 = newFocus -: goUp -: modify (\_ -> 'X')Mover-se para cima é fácil porque as migalhas que deixamos formam a parte da estrutura de dados em que não estamos focando, mas ela está invertida, algo como virar uma meia do avesso. É por isso que quando queremos subir, não temos que começar da raiz e descer, mas apenas pegamos o topo da nossa árvore invertida, desinvertendo assim uma parte dela e adicionando-a ao nosso foco.
Cada nó tem duas subárvores, mesmo que essas subárvores sejam árvores vazias. Então, se estivermos focando em uma subárvore vazia, uma coisa que podemos fazer é substituí-la por uma subárvore não vazia, anexando assim uma árvore a um nó folha. O código para isso é simples:
attach :: Tree a -> Zipper a -> Zipper a
attach t (_, bs) = (t, bs)Recebemos uma árvore e um zipper e retornamos um novo zipper que tem
seu foco substituído pela árvore fornecida. Não só podemos estender
árvores desta forma, substituindo subárvores vazias por novas árvores,
como também podemos substituir subárvores inteiras existentes. Vamos
anexar uma árvore ao extremo esquerdo da nossa
freeTree:
ghci> let farLeft = (freeTree,[]) -: goLeft -: goLeft -: goLeft -: goLeft
ghci> let newFocus = farLeft -: attach (Node 'Z' Empty Empty)newFocus está agora focado na árvore que acabamos de
anexar e o resto da árvore jaz invertido nas migalhas de pão. Se
usássemos topMost para caminhar até o topo da árvore, seria
a mesma árvore que freeTree, mas com um 'Z'
adicional no seu extremo esquerdo.
Indo direto para o topo, onde o ar é puro e limpo!
Criar uma função que caminhe até o topo da árvore, independentemente de onde estejamos focando, é realmente fácil. Aqui está ela:
topMost :: Zipper a -> Zipper a
topMost (t,[]) = (t,[])
topMost z = topMost (goUp z)Se o nosso rastro de migalhas turbinadas estiver vazio, isso
significa que já estamos na raiz da nossa árvore, então apenas
retornamos o foco atual. Caso contrário, subimos para obter o foco do nó
pai e então aplicamos recursivamente topMost a ele. Então
agora podemos caminhar pela nossa árvore, indo para a esquerda, para a
direita e para cima, aplicando modify e attach
à medida que avançamos e, quando terminarmos as nossas modificações,
usamos topMost para focar na raiz da nossa árvore e ver as
mudanças que fizemos na perspectiva adequada.
Focando em listas
Zippers podem ser usados com praticamente qualquer estrutura de dados, então não é surpresa que eles possam ser usados para focar em sublistas de listas. Afinal de contas, listas são muito parecidas com árvores, só que onde um nó em uma árvore tem um elemento (ou não) e várias subárvores, um nó em uma lista tem um elemento e apenas uma única sublista. Quando implementamos nossas próprias listas, definimos o nosso tipo de dado assim:
data List a = Empty | Cons a (List a) deriving (Show, Read, Eq, Ord)
Contraste isso com a nossa definição de árvore binária e fica fácil ver como listas podem ser vistas como árvores onde cada nó tem apenas uma subárvore.
Uma lista como [1,2,3] pode ser escrita como
1:2:3:[]. Ela consiste na cabeça da lista, que é
1, e depois na cauda da lista, que é 2:3:[].
Por sua vez, 2:3:[] também tem uma cabeça, que é
2, e uma cauda, que é 3:[]. Com
3:[], o 3 é a cabeça e a cauda é a lista vazia
[].
Vamos fazer um zipper para listas. Para mudar o foco nas sublistas de uma lista, movemo-nos para frente ou para trás (enquanto com árvores nos movíamos para cima, para a esquerda ou para a direita). A parte focada será uma subárvore e junto com ela deixaremos migalhas de pão à medida que avançamos. Agora, do que consistiria uma única migalha de pão para uma lista? Quando estávamos lidando com árvores binárias, dissemos que uma migalha tem que conter o elemento na raiz do nó pai junto com todas as subárvores que não escolhemos. Também tinha que lembrar se fomos para a esquerda ou para a direita. Então, tinha que ter toda a informação que um nó tem, exceto pela subárvore em que escolhemos focar.
Listas são mais simples que árvores, então não temos que lembrar se
fomos para a esquerda ou para a direita, porque só existe um caminho
para ir mais fundo em uma lista. Como existe apenas uma subárvore para
cada nó, também não precisamos lembrar os caminhos que não tomamos.
Parece que tudo o que temos que lembrar é o elemento anterior. Se temos
uma lista como [3,4,5] e sabemos que o elemento anterior
era 2, podemos voltar apenas colocando esse elemento no
início da nossa lista, obtendo [2,3,4,5].
Como uma única migalha de pão aqui é apenas o elemento, não
precisamos realmente colocá-lo dentro de um tipo de dado, como fizemos
quando criamos o tipo Crumb para zippers de árvores:
type ListZipper a = ([a],[a])A primeira lista representa a lista em que estamos focando e a segunda lista é a lista de migalhas de pão. Vamos fazer funções que andam para frente e para trás em listas:
goForward :: ListZipper a -> ListZipper a
goForward (x:xs, bs) = (xs, x:bs)
goBack :: ListZipper a -> ListZipper a
goBack (xs, b:bs) = (b:xs, bs)Quando estamos indo para frente, focamos na cauda da lista atual e deixamos o elemento da cabeça como uma migalha. Quando estamos nos movendo para trás, pegamos a última migalha e a colocamos no início da lista.
Aqui estão estas duas funções em ação:
ghci> let xs = [1,2,3,4]
ghci> goForward (xs,[])
([2,3,4],[1])
ghci> goForward ([2,3,4],[1])
([3,4],[2,1])
ghci> goForward ([3,4],[2,1])
([4],[3,2,1])
ghci> goBack ([4],[3,2,1])
([3,4],[2,1])Vemos que as migalhas no caso das listas nada mais são do que a parte invertida da nossa lista. O elemento do qual nos afastamos sempre vai para a cabeça das migalhas, então é fácil voltar apenas pegando esse elemento da cabeça das migalhas e tornando-o a cabeça do nosso foco.
Isso também torna mais fácil ver por que chamamos isso de zipper, porque realmente parece o cursor de um zíper movendo-se para cima e para baixo.
Se você estivesse criando um editor de texto, poderia usar uma lista de strings para representar as linhas de texto que estão abertas atualmente e então poderia usar um zipper para saber em qual linha o cursor está focado no momento. Usando um zipper, também seria mais fácil inserir novas linhas em qualquer lugar do texto ou excluir as existentes.
Um sistema de arquivos muito simples
Agora que sabemos como os zippers funcionam, vamos usar árvores para representar um sistema de arquivos muito simples e então fazer um zipper para esse sistema de arquivos, o que nos permitirá mover entre pastas, exatamente como costumamos fazer ao saltar pelo nosso sistema de arquivos.
Se tomarmos uma visão simplista do sistema de arquivos hierárquico médio, veremos que ele é composto principalmente de arquivos e pastas. Arquivos são unidades de dados e vêm com um nome, enquanto pastas são usadas para organizar those arquivos e podem conter arquivos ou outras pastas. Então, digamos que um item em um sistema de arquivos é um arquivo, que vem com um nome e alguns dados, ou uma pasta, que tem um nome e depois um monte de itens que são eles próprios arquivos ou pastas. Aqui está um tipo de dado para isso e alguns sinônimos de tipo para sabermos o que é o quê:
type Name = String
type Data = String
data FSItem = File Name Data | Folder Name [FSItem] deriving (Show)Um arquivo vem com duas strings, que representam seu nome e os dados que ele contém. Uma pasta vem com uma string que é o seu nome e uma lista de itens. Se essa lista estiver vazia, então temos uma pasta vazia.
Aqui está uma pasta com alguns arquivos e subpastas:
myDisk :: FSItem
myDisk =
Folder "root"
[ File "goat_yelling_like_man.wmv" "baaaaaa"
, File "pope_time.avi" "god bless"
, Folder "pics"
[ File "ape_throwing_up.jpg" "bleargh"
, File "watermelon_smash.gif" "smash!!"
, File "skull_man(scary).bmp" "Yikes!"
]
, File "dijon_poupon.doc" "best mustard"
, Folder "programs"
[ File "fartwizard.exe" "10gotofart"
, File "owl_bandit.dmg" "mov eax, h00t"
, File "not_a_virus.exe" "really not a virus"
, Folder "source code"
[ File "best_hs_prog.hs" "main = print (fix error)"
, File "random.hs" "main = print 4"
]
]
]Isso é na verdade o que o meu disco contém agora.
Um zipper para o nosso sistema de arquivos
Agora que temos um sistema de arquivos, tudo o que precisamos é de um zipper para podermos “zippar” e dar zoom por ele e adicionar, modificar e remover arquivos tanto quanto pastas. Como acontece com as árvores binárias e listas, vamos deixar migalhas de pão que contêm informações sobre todas as coisas que escolhemos não visitar. Como dissemos, uma única migalha de pão deve ser meio que como um nó, só que deve conter tudo exceto a subárvore em que estamos focando atualmente. Ela também deve notar onde o buraco está para que, uma vez que voltemos para cima, possamos preencher o nosso foco anterior no buraco.
Neste caso, uma migalha de pão deve ser como uma pasta, só que deve estar faltando a pasta que escolhemos atualmente. “Por que não como um arquivo?”, você pergunta. Bem, porque uma vez que estamos focando em um arquivo, não podemos nos mover mais profundamente no sistema de arquivos, então não faz sentido deixar uma migalha de pão dizendo que viemos de um arquivo. Um arquivo é algo como uma árvore vazia.
Se estamos focando na pasta "root" e depois focamos no
arquivo "dijon_poupon.doc", como deve ser a migalha de pão
que deixamos? Bem, ela deve conter o nome de sua pasta pai junto com os
itens que vêm antes do arquivo em que estamos focando e os itens que vêm
depois dele. Portanto, tudo o que precisamos é de um Name e
duas listas de itens. Ao manter listas separadas para os itens que vêm
antes do item em que estamos focando e para os itens que vêm depois
dele, saberemos exatamente onde colocá-lo quando subirmos novamente.
Desta forma, sabemos onde está o buraco.
Aqui está o nosso tipo de migalha para o sistema de arquivos:
data FSCrumb = FSCrumb Name [FSItem] [FSItem] deriving (Show)E aqui está um sinônimo de tipo para o nosso zipper:
type FSZipper = (FSItem, [FSCrumb])Voltar para cima na hierarquia é muito simples. Apenas pegamos a última migalha e montamos um novo foco a partir do foco atual e da migalha. Assim:
fsUp :: FSZipper -> FSZipper
fsUp (item, FSCrumb name ls rs:bs) = (Folder name (ls ++ [item] ++ rs), bs)Como nossa migalha sabia qual era o nome da pasta pai, bem como os
itens que vinham antes do nosso item focado na pasta (que é
ls) e os que vinham depois (que é rs), subir
foi fácil.
E quanto a ir mais fundo no sistema de arquivos? Se estivermos no
"root" e quisermos focar em
"dijon_poupon.doc", a migalha que deixaremos incluirá o
nome "root" junto com os itens que precedem
"dijon_poupon.doc" e os que vêm depois dele.
Aqui está uma função que, dado um nome, foca em um arquivo ou pasta localizado na pasta focada atual:
import Data.List (break)
fsTo :: Name -> FSZipper -> FSZipper
fsTo name (Folder folderName items, bs) =
let (ls, item:rs) = break (nameIs name) items
in (item, FSCrumb folderName ls rs:bs)
nameIs :: Name -> FSItem -> Bool
nameIs name (Folder folderName _) = name == folderName
nameIs name (File fileName _) = name == fileNamefsTo recebe um Name e uma
FSZipper e retorna uma nova FSZipper que foca
no arquivo com o nome dado. Esse arquivo tem que estar na pasta focada
atual. Esta função não procura por todos os lados, ela apenas olha para
a pasta atual.

Primeiro usamos break para quebrar a lista de itens em
uma pasta naqueles que precedem o arquivo que estamos procurando e
naqueles que vêm depois dele. Se você se lembra, break
recebe um predicado e uma lista e retorna um par de listas. A primeira
lista no par guarda os itens para os quais o predicado retorna
False. Então, uma vez que o predicado retorna
True para um item, ela coloca esse item e o resto da lista
no segundo item do par. Criamos uma função auxiliar chamada
nameIs que recebe um nome e um item do sistema de arquivos
e retorna True se os nomes coincidirem.
Então agora, ls é uma lista que contém os itens que
precedem o item que estamos procurando, item é esse próprio
item e rs é a lista de itens que vêm depois dele na sua
pasta. Agora que temos isso, apenas apresentamos o item que obtivemos do
break como o foco e construímos uma migalha que tem todos
os dados de que precisa.
Observe que se o nome que estamos procurando não estiver na pasta, o
padrão item:rs tentará fazer match em uma lista vazia e
teremos um erro.
Manipulando o nosso sistema de arquivos
Além disso, se o nosso foco atual não for uma pasta, mas um arquivo, também recebemos um erro e o programa trava.
Agora podemos nos mover para cima e para baixo no nosso sistema de
arquivos. Imaginemos que começamos na raiz e caminhamos até o arquivo
"skull_man(scary).bmp":
ghci> let newFocus = (myDisk,[]) -: fsTo "pics" -: fsTo "skull_man(scary).bmp"newFocus agora é um zipper focado no arquivo
"skull_man(scary).bmp". Vamos pegar o primeiro componente
do zipper (o foco em si) e ver se isso é realmente verdade:
ghci> fst newFocus
File "skull_man(scary).bmp" "Yikes!"Vamos subir e focar no arquivo vizinho
"watermelon_smash.gif":
ghci> let newFocus2 = newFocus -: fsUp -: fsTo "watermelon_smash.gif"
ghci> fst newFocus2
File "watermelon_smash.gif" "smash!!"Agora que sabemos como navegar no nosso sistema de arquivos, manipulá-lo é fácil. Aqui está uma função que renomeia o arquivo ou pasta atualmente focado:
fsRename :: Name -> FSZipper -> FSZipper
fsRename newName (Folder name items, bs) = (Folder newName items, bs)
fsRename newName (File name dat, bs) = (File newName dat, bs)Agora podemos renomear nossa pasta "pics" para
"cspi":
ghci> let newFocus = (myDisk,[]) -: fsTo "pics" -: fsRename "cspi" -: fsUpDescemos até a pasta "pics", renomeamo-la e depois
subimos novamente.
Que tal uma função que cria um novo item na pasta atual? Contemple:
fsNewFile :: FSItem -> FSZipper -> FSZipper
fsNewFile item (Folder folderName items, bs) =
(Folder folderName (item:items), bs)Fácil como um abraço. Observe que isso travaria se tentássemos adicionar um item mas não estivéssemos focando em uma pasta, mas sim em um arquivo.
Vamos adicionar um arquivo à nossa pasta "pics" e depois
subir de volta para a raiz:
ghci> let newFocus = (myDisk,[]) -: fsTo "pics" -: fsNewFile (File "heh.jpg" "lol") -: fsUpO que é realmente legal sobre tudo isso é que, quando modificamos o
nosso sistema de arquivos, ele não o modifica realmente no lugar, mas
retorna um sistema de arquivos inteiramente novo. Dessa forma, temos
acesso ao nosso antigo sistema de arquivos (neste caso,
myDisk), bem como ao novo (o primeiro componente de
newFocus). Assim, ao usar zippers, ganhamos versionamento
de graça, o que significa que podemos sempre nos referir a versões mais
antigas das estruturas de dados mesmo depois de as termos mudado, por
assim dizer. Isso não é exclusividade dos zippers, mas é uma propriedade
do Haskell porque as suas estruturas de dados são imutáveis. Com
zippers, no entanto, ganhamos a habilidade de caminhar de forma fácil e
eficiente pelas nossas estruturas de dados, de modo que a persistência
das estruturas de dados do Haskell realmente começa a brilhar.
Cuidado onde pisa
Até agora, enquanto caminhávamos pelas nossas estruturas de dados,
fossem elas árvores binárias, listas ou sistemas de arquivos, não nos
importávamos muito se dermos um passo longe demais e caíssemos. Por
exemplo, a nossa função goLeft recebe um zipper de uma
árvore binária e move o foco para a sua subárvore esquerda:
goLeft :: Zipper a -> Zipper a
goLeft (Node x l r, bs) = (l, LeftCrumb x r:bs)
Mas e se a árvore da qual estamos saindo for uma árvore vazia? Ou
seja, e se não for um Node, mas um Empty?
Neste caso, receberíamos um erro em tempo de execução porque o pattern
match falharia e não fizemos nenhum padrão para lidar com uma árvore
vazia, que não tem nenhuma subárvore. Até agora, apenas assumimos que
nunca tentaríamos focar na subárvore esquerda de uma árvore vazia, já
que sua subárvore esquerda não existe. Mas ir para a subárvore esquerda
de uma árvore vazia não faz muito sentido, e até agora apenas
convenientemente ignoramos isso.
Ou e se já estivéssemos na raiz de alguma árvore e não tivéssemos nenhuma migalha de pão, mas ainda tentássemos subir? A mesma coisa aconteceria. Parece que, ao usar zippers, qualquer passo pode ser o nosso último (insira uma música sinistra aqui). Em outras palavras, qualquer movimento pode resultar em sucesso, mas também pode resultar em falha. Isso te lembra de algo? Claro, Monads! Mais especificamente, a Maybe Monad, que adiciona um contexto de possível falha aos valores normais.
Então, vamos usar a Maybe Monad para adicionar um contexto de
possível falha aos nossos movimentos. Vamos pegar as funções que
trabalham no nosso zipper de árvore binária e vamos transformá-las em
monadic functions. Primeiro, vamos cuidar da possível falha em
goLeft e goRight. Até agora, a falha das
funções que poderiam falhar foi sempre refletida no seu resultado, e
desta vez não é diferente. Aqui estão goLeft e
goRight com uma possibilidade adicional de falha:
goLeft :: Zipper a -> Maybe (Zipper a)
goLeft (Node x l r, bs) = Just (l, LeftCrumb x r:bs)
goLeft (Empty, _) = Nothing
goRight :: Zipper a -> Maybe (Zipper a)
goRight (Node x l r, bs) = Just (r, RightCrumb x l:bs)
goRight (Empty, _) = NothingLegal, agora se tentarmos dar um passo à esquerda de uma árvore
vazia, recebemos um Nothing!
ghci> goLeft (Empty, [])
Nothing
ghci> goLeft (Node 'A' Empty Empty, [])
Just (Empty,[LeftCrumb 'A' Empty])Parece bom! E quanto a subir? O problema antes acontecia se
tentássemos subir mas não tivéssemos mais migalhas de pão, o que
significava que já estávamos na raiz da árvore. Esta é a função
goUp que lança um erro se não nos mantivermos dentro dos
limites da nossa árvore:
goUp :: Zipper a -> Zipper a
goUp (t, LeftCrumb x r:bs) = (Node x t r, bs)
goUp (t, RightCrumb x l:bs) = (Node x l t, bs)Agora vamos modificá-la para falhar graciosamente:
goUp :: Zipper a -> Maybe (Zipper a)
goUp (t, LeftCrumb x r:bs) = Just (Node x t r, bs)
goUp (t, RightCrumb x l:bs) = Just (Node x l t, bs)
goUp (_, []) = NothingSe tivermos migalhas de pão, tudo está bem e retornamos um novo foco com sucesso, mas se não tivermos, retornamos uma falha.
Antes, estas funções recebiam zippers e retornavam zippers, o que significava que podíamos encadeá-las assim para caminhar:
ghci> let newFocus = (freeTree,[]) -: goLeft -: goRightMas agora, em vez de retornar Zipper a, elas retornam
Maybe (Zipper a), então encadear funções desta forma não
funcionará. Tivemos um problema semelhante quando estávamos lidando com o nosso
equilibrista no capítulo sobre Monads. Ele também caminhava um passo
de cada vez e cada um dos seus passos poderia resultar em falha porque
um bando de pássaros poderia pousar num dos lados da sua vara de
equilíbrio e fazê-lo cair.
Agora, a piada é conosco porque somos nós que estamos caminhando e
estamos atravessando um labirinto de nossa própria autoria. Felizmente,
podemos aprender com o equilibrista e apenas fazer o que ele fez, que é
trocar a aplicação normal de funções pelo uso de >>=,
que recebe um valor com um contexto (no nosso caso, o
Maybe (Zipper a), que tem um contexto de possível falha) e
o alimenta numa função enquanto garante que o contexto seja cuidado.
Então, assim como o nosso equilibrista, vamos trocar todos os nossos
operadores -: por >>=. Tudo bem, podemos
encadear as nossas funções novamente! Veja:
ghci> let coolTree = Node 1 Empty (Node 3 Empty Empty)
ghci> return (coolTree,[]) >>= goRight
Just (Node 3 Empty Empty,[RightCrumb 1 Empty])
ghci> return (coolTree,[]) >>= goRight >>= goRight
Just (Empty,[RightCrumb 3 Empty,RightCrumb 1 Empty])
ghci> return (coolTree,[]) >>= goRight >>= goRight >>= goRight
NothingUsamos o return para colocar um zipper num
Just e depois usamos o >>= para
alimentar isso para a nossa função goRight. Primeiro,
criamos uma árvore que tem à sua esquerda uma subárvore vazia e à sua
direita um nó que tem duas subárvores vazias. Quando tentamos ir para a
direita uma vez, o resultado é um sucesso, porque a operação faz
sentido. Ir para a direita duas vezes também está tudo bem; acabamos com
o foco numa subárvore vazia. Mas ir para a direita três vezes não faria
sentido, porque não podemos ir para a direita de uma subárvore vazia,
razão pela qual o resultado é um Nothing.
Agora equipamos as nossas árvores com uma rede de segurança que nos pegará caso caiamos. Uau, eu arrasei nesta metáfora.
O nosso sistema de arquivos também tem muitos casos em que uma operação pode falhar, como tentar focar num arquivo ou pasta que não existe. Como exercício, você pode equipar o nosso sistema de arquivos com funções que falham graciosamente usando a Maybe Monad.