Por um Punhado de Monads
Quando falamos pela primeira vez sobre Functors, vimos que eles eram um conceito útil para valores que podem ser mapeados. Então, levamos esse conceito um passo adiante introduzindo Applicative Functors, que nos permitem ver valores de certos tipos de dados como valores com contextos e usar funções normais nesses valores, preservando o significado desses contextos.
Neste capítulo, aprenderemos sobre Monads, que são apenas Applicative Functors anabolizados, assim como Applicative Functors são apenas Functors anabolizados.
Quando começamos com Functors, vimos que é possível mapear funções
sobre vários tipos de dados. Vimos que para este propósito, a typeclass
Functor foi introduzida e ela nos fez perguntar: quando
temos uma função do tipo a -> b e algum tipo de dado
f a, como mapeamos essa função sobre o tipo de dado para
terminar com f b? Vimos como mapear algo sobre um
Maybe a, uma lista [a], um IO a
etc. Até vimos como mapear uma função a -> b sobre
outras funções do tipo r -> a para obter funções do tipo
r -> b. Para responder a essa pergunta de como mapear
uma função sobre algum tipo de dado, tudo o que tivemos que fazer foi
olhar para o tipo de fmap:
fmap :: (Functor f) => (a -> b) -> f a -> f bE então fazê-lo funcionar para o nosso tipo de dado escrevendo a
instância de Functor apropriada.
Então vimos uma possível melhoria dos Functors e dissemos, ei, e se
essa função a -> b já estiver embrulhada dentro de um
valor Functor? Tipo, e se tivermos Just (*3), como
aplicamos isso a Just 5? E se não quisermos aplicá-lo a
Just 5, mas a um Nothing em vez disso? Ou se
tivermos [(*2),(+4)], como aplicaríamos isso a
[1,2,3]? Como isso funcionaria afinal? Para isso, a
typeclass Applicative foi introduzida, na qual queríamos a
resposta para o seguinte tipo:
(<*>) :: (Applicative f) => f (a -> b) -> f a -> f bTambém vimos que podemos pegar um valor normal e embrulhá-lo dentro
de um tipo de dado. Por exemplo, podemos pegar um 1 e
embrulhá-lo para que se torne um Just 1. Ou podemos
transformá-lo em um [1]. Ou uma ação de E/S que não faz
nada e apenas produz 1. A função que faz isso é chamada
pure.
Como dissemos, um valor Applicative pode ser visto como um valor com
um contexto adicionado. Um valor chique, para colocar em termos
técnicos. Por exemplo, o caractere 'a' é apenas um
caractere normal, enquanto Just 'a' tem algum contexto
adicionado. Em vez de um Char, temos um
Maybe Char, que nos diz que seu valor pode ser um
caractere, mas também pode ser uma ausência de caractere.
Foi legal ver como a typeclass Applicative nos permitiu
usar funções normais nesses valores com contexto e como esse contexto
foi preservado. Observe:
ghci> (*) <$> Just 2 <*> Just 8
Just 16
ghci> (++) <$> Just "klingon" <*> Nothing
Nothing
ghci> (-) <$> [3,4] <*> [1,2,3]
[2,1,0,3,2,1]Ah, legal, então agora que os tratamos como valores Applicatives,
valores Maybe a representam computações que podem ter
falhado, valores [a] representam computações que têm vários
resultados (computações não determinísticas), valores IO a
representam valores que têm efeitos colaterais, etc.
Monads são uma extensão natural de Applicative Functors e com elas
estamos preocupados com isso: se você tem um valor com um contexto,
m a, como você aplica a ele uma função que pega um
a normal e retorna um valor com um contexto? Ou seja, como
você aplica uma função do tipo a -> m b a um valor do
tipo m a? Então, essencialmente, vamos querer esta
função:
(>>=) :: (Monad m) => m a -> (a -> m b) -> m bSe temos um valor chique e uma função que pega um valor
normal, mas retorna um valor chique, como alimentamos esse valor chique
na função? Esta é a principal questão com a qual nos
preocuparemos ao lidar com Monads. Escrevemos m a em vez de
f a because o m significa Monad,
mas Monads são apenas Applicative Functors que suportam
>>=. A função >>= é pronunciada
como bind.
Quando temos um valor normal a e uma função normal
a -> b, é muito fácil alimentar o valor para a função —
você apenas aplica a função ao valor normalmente e é isso. Mas quando
estamos lidando com valores que vêm com certos contextos, é preciso
pensar um pouco para ver como esses valores chiques são alimentados para
funções e como levar em consideração seu comportamento, mas você verá
que é fácil como um dois três.
Molhando os pés com Maybe

Agora que temos uma vaga ideia sobre o que são Monads, vamos ver se podemos tornar essa ideia um pouco menos vaga.
Para surpresa de ninguém, Maybe é uma Monad, então vamos
explorá-la um pouco mais e ver se podemos combiná-la com o que sabemos
sobre Monads.
Certifique-se de entender Applicatives
neste ponto. É bom se você tiver uma noção de como as várias instâncias
Applicative funcionam e que tipo de computações elas
representam, porque Monads nada mais são do que pegar nosso conhecimento
Applicative existente e atualizá-lo.
Um valor do tipo Maybe a representa um valor do tipo
a com o contexto de possível falha anexado. Um valor de
Just "dharma" significa que a string "dharma"
está lá, enquanto um valor de Nothing representa sua
ausência, ou se você olhar para a string como o resultado de uma
computação, significa que a computação falhou.
Quando olhamos para Maybe como um Functor, vimos que se
queremos fazer fmap de uma função sobre ele, ela é mapeada
sobre o interior se for um valor Just, caso contrário, o
Nothing é mantido porque não há nada sobre o que
mapeá-la!
Assim:
ghci> fmap (++"!") (Just "wisdom")
Just "wisdom!"
ghci> fmap (++"!") Nothing
NothingComo um Applicative Functor, ele funciona de forma semelhante. No
entanto, Applicatives também têm a função embrulhada. Maybe
é um Applicative Functor de tal forma que quando usamos
<*> para aplicar uma função dentro de um
Maybe a um valor que está dentro de um Maybe,
ambos têm que ser valores Just para que o resultado seja um
valor Just, caso contrário, o resultado é
Nothing. Faz sentido porque se você está perdendo a função
ou a coisa a qual você está aplicando, você não pode inventar algo do
nada, então você tem que propagar a falha:
ghci> Just (+3) <*> Just 3
Just 6
ghci> Nothing <*> Just "greed"
Nothing
ghci> Just ord <*> Nothing
NothingQuando usamos o Applicative style para ter funções normais agindo
sobre valores Maybe, é semelhante. Todos os valores têm que
ser valores Just, caso contrário, é tudo por
Nothing (nada)!
ghci> max <$> Just 3 <*> Just 6
Just 6
ghci> max <$> Just 3 <*> Nothing
NothingE agora, vamos pensar sobre como faríamos >>= para
Maybe. Como dissemos, >>= pega um valor
monádico e uma função que pega um valor normal e retorna um valor
monádico e consegue aplicar essa função ao valor monádico. Como ele faz
isso, se a função pega um valor normal? Bem, para fazer isso, ele tem
que levar em conta o contexto desse valor monádico.
Neste caso, >>= pegaria um valor
Maybe a e uma função do tipo a -> Maybe b e
de alguma forma aplicaria a função ao Maybe a. Para
descobrir como ele faz isso, podemos usar a intuição que temos de
Maybe sendo um Applicative Functor. Digamos que temos uma
função \x -> Just (x+1). Ela pega um número, adiciona
1 a ele e o embrulha em um Just:
ghci> (\x -> Just (x+1)) 1
Just 2
ghci> (\x -> Just (x+1)) 100
Just 101Se o alimentarmos com 1, ele avalia para
Just 2. Se dermos a ele o número 100, o
resultado é Just 101. Muito direto. Agora aqui está o ponto
crucial: como alimentamos um valor Maybe para essa função?
Se pensarmos sobre como Maybe age como um Applicative
Functor, responder a isso é muito fácil. Se o alimentarmos com um valor
Just, pegue o que está dentro do Just e
aplique a função a ele. Se dermos a ele um Nothing, hmm,
bem, então ficamos com uma função, mas Nothing (nada) para
aplicar a ela. Nesse caso, vamos apenas fazer o que fizemos antes e
dizer que o resultado é Nothing.
Em vez de chamá-lo >>=, vamos chamá-lo de
applyMaybe por enquanto. Ele pega um Maybe a e
uma função que retorna um Maybe b e consegue aplicar essa
função ao Maybe a. Aqui está em código:
applyMaybe :: Maybe a -> (a -> Maybe b) -> Maybe b
applyMaybe Nothing f = Nothing
applyMaybe (Just x) f = f xOk, agora vamos brincar com isso um pouco. Vamos usá-lo como uma
função infixa para que o valor Maybe esteja no lado
esquerdo e a função no direito:
ghci> Just 3 `applyMaybe` \x -> Just (x+1)
Just 4
ghci> Just "smile" `applyMaybe` \x -> Just (x ++ " :)")
Just "smile :)"
ghci> Nothing `applyMaybe` \x -> Just (x+1)
Nothing
ghci> Nothing `applyMaybe` \x -> Just (x ++ " :)")
NothingNo exemplo acima, vemos que quando usamos applyMaybe com
um valor Just e uma função, a função simplesmente foi
aplicada ao valor dentro do Just. Quando tentamos usá-lo
com um Nothing, todo o resultado foi Nothing.
E se a função retornar um Nothing? Vamos ver:
ghci> Just 3 `applyMaybe` \x -> if x > 2 then Just x else Nothing
Just 3
ghci> Just 1 `applyMaybe` \x -> if x > 2 then Just x else Nothing
NothingExatamente o que esperávamos. Se o valor monádico à esquerda for um
Nothing, a coisa toda é Nothing. E se a função
à direita retornar um Nothing, o resultado é
Nothing novamente. Isso é muito semelhante a quando usamos
Maybe como um Applicative e obtivemos um resultado
Nothing se algo ali dentro fosse um
Nothing.
Parece que para Maybe, descobrimos como pegar um valor
chique e alimentá-lo a uma função que pega um valor normal e retorna um
chique. Fizemos isso mantendo em mente que um valor Maybe
representa uma computação que pode ter falhado.
Você pode estar se perguntando, como isso é útil? Pode parecer que Applicative Functors são mais fortes que Monads, já que Applicative Functors nos permitem pegar uma função normal e fazê-la operar em valores com contextos. Veremos que Monads podem fazer isso também porque são uma atualização de Applicative Functors, e que elas também podem fazer algumas coisas legais que Applicative Functors não podem.
Voltaremos ao Maybe em um minuto, mas primeiro, vamos
verificar a typeclass que pertence às Monads.
A typeclass Monad
Así como Functors têm a typeclass Functor e Applicative
Functors têm a typeclass Applicative, Monads vêm com sua
própria typeclass: Monad! Uau, quem diria? É assim que a
typeclass se parece:
class Monad m where
return :: a -> m a
(>>=) :: m a -> (a -> m b) -> m b
(>>) :: m a -> m b -> m b
x >> y = x >>= \_ -> y
fail :: String -> m a
fail msg = error msg
Vamos começar com a primeira linha. Diz
class Monad m where. Mas espere, não dissemos que Monads
são apenas Applicative Functors anabolizados? Não deveria haver uma
restrição de classe lá na linha de
class (Applicative m) => Monad m where para que um tipo
tenha que ser um Applicative Functor primeiro antes de poder ser feito
uma Monad? Bem, deveria, mas quando Haskell foi feito, não ocorreu às
pessoas que Applicative Functors são um bom ajuste para Haskell, então
eles não estavam lá. Mas fique tranquilo, toda Monad é um Applicative
Functor, mesmo que a declaração da classe Monad não diga
isso.
A primeira função que a typeclass Monad define é
return. É a mesma que pure, apenas com um nome
diferente. Seu tipo é (Monad m) => a -> m a. Ela pega
um valor e o coloca em um contexto padrão mínimo que ainda contém esse
valor. Em outras palavras, ela pega algo e o embrulha em uma Monad. Ela
sempre faz a mesma coisa que a função pure da typeclass
Applicative, o que significa que já estamos familiarizados
com return. Já usamos return ao fazer E/S. Nós
a usamos para pegar um valor e fazer uma ação de E/S falsa que não faz
nada além de produzir esse valor. Para Maybe, ela pega um
valor e o embrulha em um Just.
Apenas um lembrete: return não é nada parecido com o
return que está na maioria das outras linguagens. Ele não
encerra a execução da função ou algo assim, ele apenas pega um valor
normal e o coloca em um contexto.

É como a aplicação de função, só que em vez de pegar um valor normal e alimentá-lo a uma função normal, ela pega um valor monadic (ou seja, um valor com um contexto) e o alimenta a uma função que pega um valor normal, mas retorna um valor monadic.
Em seguida, temos >>. Não vamos prestar muita
atenção a isso por enquanto, porque vem com uma implementação padrão e
praticamente nunca a implementamos ao fazer instâncias de
Monad.
A função final da typeclass Monad é fail.
Nunca a usamos explicitamente em nosso código. Em vez disso, ela é usada
pelo Haskell para permitir falha em uma construção sintática especial
para Monads que encontraremos mais tarde. Não precisamos nos preocupar
muito com fail por enquanto.
Agora que sabemos como é a typeclass Monad, vamos ver
como Maybe é uma instância de Monad!
instance Monad Maybe where
return x = Just x
Nothing >>= f = Nothing
Just x >>= f = f x
fail _ = Nothingreturn é o mesmo que pure, então esse é
fácil. Fazemos o que fizemos na typeclass Applicative e o
embrulhamos em um Just.
A função >>= é a mesma que nossa
applyMaybe. Ao alimentar o Maybe a para nossa
função, mantemos em mente o contexto e retornamos um
Nothing se o valor à esquerda for Nothing
porque se não houver valor, então não há como aplicar nossa função a
ele. Se for um Just, pegamos o que está dentro e aplicamos
f a ele.
Podemos brincar com Maybe como uma Monad:
ghci> return "WHAT" :: Maybe String
Just "WHAT"
ghci> Just 9 >>= \x -> return (x*10)
Just 90
ghci> Nothing >>= \x -> return (x*10)
NothingNada novo ou emocionante na primeira linha, já que já usamos
pure com Maybe e sabemos que
return é apenas pure com um nome diferente. As
duas linhas seguintes mostram >>= um pouco mais.
Observe como quando alimentamos Just 9 para a função
\x -> return (x*10), o x assumiu o valor
9 dentro da função. Parece que fomos capazes de extrair o
valor de um Maybe sem pattern matching. E ainda não
perdemos o contexto de nosso valor Maybe, porque quando é
Nothing, o resultado de usar >>= será
Nothing também.
Andando na linha

Agora que sabemos como alimentar um valor Maybe a para
uma função do tipo a -> Maybe b levando em consideração
o contexto de possível falha, vamos ver como podemos usar
>>= repetidamente para lidar com computações de
vários valores Maybe a.
Pierre decidiu dar um tempo em seu trabalho na fazenda de peixes e tentar andar na corda bamba. Ele não é tão ruim nisso, mas tem um problema: pássaros continuam pousando em sua vara de equilíbrio! Eles vêm e tiram um breve descanso, conversam com seus amigos aviários e depois decolam em busca de migalhas de pão. Isso não o incomodaria tanto se o número de pássaros no lado esquerdo da vara fosse sempre igual ao número de pássaros no lado direito. Mas às vezes, todos os pássaros decidem que gostam mais de um lado e então o desequilibram, o que resulta em uma queda embaraçosa para Pierre (ele está usando uma rede de segurança).
Digamos que ele mantenha o equilíbrio se o número de pássaros no lado esquerdo da vara e no lado direito da vara estiver dentro de três. Então, se houver um pássaro no lado direito e quatro pássaros no lado esquerdo, ele está bem. Mas se um quinto pássaro pousar no lado esquerdo, então ele perde o equilíbrio e mergulha.
Vamos simular pássaros pousando e voando da vara e ver se Pierre ainda está lá depois de um certo número de chegadas e partidas de pássaros. Por exemplo, queremos ver o que acontece com Pierre se primeiro um pássaro chegar no lado esquerdo, depois quatro pássaros ocuparem o lado direito e então o pássaro que estava no lado esquerdo decidir voar para longe.
Podemos representar a vara com um simples par de inteiros. O primeiro componente significará o número de pássaros no lado esquerdo e o segundo componente o número de pássaros no lado direito:
type Birds = Int
type Pole = (Birds,Birds)Primeiro fizemos um sinônimo de tipo para Int, chamado
Birds, porque estamos usando inteiros para representar
quantos pássaros existem. E então fizemos um sinônimo de tipo
(Birds,Birds) e o chamamos de Pole (não
confundir com uma pessoa de ascendência polonesa).
Em seguida, que tal fazermos uma função que pega um número de pássaros e os pousa em um lado da vara. Aqui estão as funções:
landLeft :: Birds -> Pole -> Pole
landLeft n (left,right) = (left + n,right)
landRight :: Birds -> Pole -> Pole
landRight n (left,right) = (left,right + n)Coisa bem direta. Vamos testá-las:
ghci> landLeft 2 (0,0)
(2,0)
ghci> landRight 1 (1,2)
(1,3)
ghci> landRight (-1) (1,2)
(1,1)Para fazer os pássaros voarem para longe, apenas fizemos um número
negativo de pássaros pousar em um lado. Como pousar um pássaro no
Pole retorna um Pole, podemos encadear
aplicações de landLeft e landRight:
ghci> landLeft 2 (landRight 1 (landLeft 1 (0,0)))
(3,1)Quando aplicamos a função landLeft 1 a
(0,0), obtemos (1,0). Então, pousamos um
pássaro no lado direito, resultando em (1,1). Finalmente,
dois pássaros pousam no lado esquerdo, resultando em (3,1).
Aplicamos uma função a algo escrevendo primeiro a função e depois
escrevendo seu parâmetro, mas aqui seria melhor se a vara fosse primeiro
e depois a função de pouso. Se fizermos uma função como esta:
x -: f = f xPodemos aplicar funções escrevendo primeiro o parâmetro e depois a função:
ghci> 100 -: (*3)
300
ghci> True -: not
False
ghci> (0,0) -: landLeft 2
(2,0)Ao usar isso, podemos pousar pássaros repetidamente na vara de uma maneira mais legível:
ghci> (0,0) -: landLeft 1 -: landRight 1 -: landLeft 2
(3,1)Muito legal! Este exemplo é equivalente ao anterior, onde pousamos
repetidamente pássaros na vara, só que parece mais organizado. Aqui, é
mais óbvio que começamos com (0,0) e depois pousamos um
pássaro na esquerda, depois um na direita e finalmente dois na
esquerda.
So far so good, mas o que acontece se 10 pássaros pousarem em um lado?
ghci> landLeft 10 (0,3)
(10,3)Pode parecer que está tudo bem, mas se você seguir os passos aqui,
verá que em um momento há 4 pássaros no lado direito e nenhum pássaro no
lado esquerdo! Para consertar isso, temos que dar outra olhada em nossas
funções landLeft e landRight. Pelo que vimos,
queremos que essas funções sejam capazes de falhar. Ou seja, queremos
que elas retornem uma nova vara se o equilíbrio estiver ok, mas falhem
se os pássaros pousarem de maneira desequilibrada. E que melhor maneira
de adicionar um contexto de falha ao valor do que usando
Maybe! Vamos refazer essas funções:
landLeft :: Birds -> Pole -> Maybe Pole
landLeft n (left,right)
| abs ((left + n) - right) < 4 = Just (left + n, right)
| otherwise = Nothing
landRight :: Birds -> Pole -> Maybe Pole
landRight n (left,right)
| abs (left - (right + n)) < 4 = Just (left, right + n)
| otherwise = NothingEm vez de retornar um Pole, essas funções agora retornam
um Maybe Pole. Elas ainda pegam o número de pássaros e a
vara antiga como antes, mas então verificam se pousar tantos pássaros na
vara desequilibraria Pierre. Usamos guardas para verificar se a
diferença entre o número de pássaros na nova vara é menor que 4. Se for,
embrulhamos a nova vara em um Just e a retornamos. Se não
for, retornamos um Nothing, indicando falha.
Vamos dar uma chance a esses bebês:
ghci> landLeft 2 (0,0)
Just (2,0)
ghci> landLeft 10 (0,3)
NothingLegal! Quando pousamos pássaros sem desequilibrar Pierre, obtemos uma
nova vara embrulhada em um Just. Mas quando muitos mais
pássaros acabam em um lado da vara, obtemos um Nothing.
Isso é legal, mas parece que perdemos a capacidade de pousar pássaros
repetidamente na vara. Não podemos mais fazer
landLeft 1 (landRight 1 (0,0)) porque quando aplicamos
landRight 1 a (0,0), não obtemos um
Pole, mas um Maybe Pole.
landLeft 1 pega um Pole e não um
Maybe Pole.
Precisamos de uma maneira de pegar um Maybe Pole e
alimentá-lo a uma função que pega um Pole e retorna um
Maybe Pole. Felizmente, temos >>=, que
faz exatamente isso para Maybe. Vamos tentar:
ghci> landRight 1 (0,0) >>= landLeft 2
Just (2,1)Lembre-se, landLeft 2 tem um tipo de
Pole -> Maybe Pole. Não poderíamos simplesmente
alimentá-lo com o Maybe Pole que é o resultado de
landRight 1 (0,0), então usamos >>= para
pegar esse valor com um contexto e dá-lo a landLeft 2.
>>= de fato nos permite tratar o valor
Maybe como um valor com contexto, porque se alimentarmos um
Nothing em landLeft 2, o resultado é
Nothing e a falha é propagada:
ghci> Nothing >>= landLeft 2
NothingCom isso, agora podemos encadear pousos que podem falhar porque
>>= nos permite alimentar um valor monadic a uma
função que pega um normal.
Aqui está uma sequência de pousos de pássaros:
ghci> return (0,0) >>= landRight 2 >>= landLeft 2 >>= landRight 2
Just (2,4)No início, usamos return para pegar uma vara e
embrulhá-la em um Just. Poderíamos ter apenas aplicado
landRight 2 a (0,0), teria sido o mesmo, mas
desta forma podemos ser mais consistentes usando >>=
para cada função. Just (0,0) é alimentado para
landRight 2, resultando em Just (0,2). Isso,
por sua vez, é alimentado para landLeft 2, resultando em
Just (2,2), e assim por diante.
Lembre-se deste exemplo de antes de introduzirmos falha na rotina de Pierre:
ghci> (0,0) -: landLeft 1 -: landRight 4 -: landLeft (-1) -: landRight (-2)
(0,2)Não simulou muito bem a interação dele com os pássaros porque no meio
ali o equilíbrio dele estava ruim, mas o resultado não refletiu isso.
Mas vamos tentar isso agora usando aplicação monadic
(>>=) em vez de aplicação normal:
ghci> return (0,0) >>= landLeft 1 >>= landRight 4 >>= landLeft (-1) >>= landRight (-2)
Nothing
Incrível. O resultado final representa falha, que é o que
esperávamos. Vamos ver como esse resultado foi obtido. Primeiro,
return coloca (0,0) em um contexto padrão,
tornando-o um Just (0,0). Então,
Just (0,0) >>= landLeft 1 acontece. Como o
Just (0,0) é um valor Just,
landLeft 1 é aplicado a (0,0), resultando em
um Just (1,0), porque os pássaros ainda estão relativamente
equilibrados. Em seguida, Just (1,0) >>= landRight 4
ocorre e o resultado é Just (1,4) pois o equilíbrio dos
pássaros ainda está intacto, embora por pouco. Just (1,4) é
alimentado para landLeft (-1). Isso significa que
landLeft (-1) (1,4) ocorre. Agora, por causa de como
landLeft funciona, isso resulta em um Nothing,
porque a vara resultante está desequilibrada. Agora que temos um
Nothing, ele é alimentado para landRight (-2),
mas como é um Nothing, o resultado é automaticamente
Nothing, já que não temos nada para aplicar
landRight (-2).
Não poderíamos ter conseguido isso apenas usando Maybe
como um Applicative. Se você tentar, ficará preso, porque Applicative
Functors não permitem que os valores Applicatives interajam muito entre
si. Eles podem, no máximo, ser usados como parâmetros para uma função
usando o Applicative style. Os Applicative operators buscarão seus
resultados e os alimentarão para a função de uma maneira apropriada para
cada Applicative e então montarão o valor Applicative final, mas não há
tanta interação acontecendo entre eles. Aqui, no entanto, cada passo
depende do resultado do anterior. Em cada pouso, o possível resultado do
anterior é examinado e a vara é verificada quanto ao equilíbrio. Isso
determina se o pouso terá sucesso ou falhará.
Também podemos criar uma função que ignora o número atual de pássaros
na vara de equilíbrio e apenas faz Pierre escorregar e cair. Podemos
chamá-la de banana:
banana :: Pole -> Maybe Pole
banana _ = NothingAgora podemos encadeá-la com nossos pousos de pássaros. Ela sempre fará nosso equilibrista cair, porque ignora o que quer que seja passado para ela e sempre retorna uma falha. Confira:
ghci> return (0,0) >>= landLeft 1 >>= banana >>= landRight 1
NothingO valor Just (1,0) é alimentado para
banana, mas ela produz um Nothing, o que faz
com que tudo resulte em um Nothing. Que infelicidade!
Em vez de fazer funções que ignoram sua entrada e apenas retornam um
monadic value predeterminado, podemos usar a função
>>, cuja implementação padrão é esta:
(>>) :: (Monad m) => m a -> m b -> m b
m >> n = m >>= \_ -> nNormalmente, passar algum valor para uma função que ignora seu
parâmetro e sempre retorna apenas algum valor predeterminado sempre
resultaria nesse valor predeterminado. Com Monads, no entanto, seu
contexto e significado também devem ser considerados. Aqui está como
>> age com Maybe:
ghci> Nothing >> Just 3
Nothing
ghci> Just 3 >> Just 4
Just 4
ghci> Just 3 >> Nothing
NothingSe você substituir >> por
>>= \_ ->, é fácil ver por que ele age como
age.
Podemos substituir nossa função banana na cadeia por um
>> e, em seguida, um Nothing:
ghci> return (0,0) >>= landLeft 1 >> Nothing >>= landRight 1
NothingAí está, falha garantida e óbvia!
Também vale a pena dar uma olhada em como isso ficaria se não
tivéssemos feito a escolha inteligente de tratar valores
Maybe como valores com um contexto de falha e alimentá-los
para funções como fizemos. Aqui está como uma série de pousos de
pássaros se pareceria:
routine :: Maybe Pole
routine = case landLeft 1 (0,0) of
Nothing -> Nothing
Just pole1 -> case landRight 4 pole1 of
Nothing -> Nothing
Just pole2 -> case landLeft 2 pole2 of
Nothing -> Nothing
Just pole3 -> landLeft 1 pole3
Pousamos um pássaro na esquerda e então examinamos a possibilidade de
falha e a possibilidade de sucesso. No caso de falha, retornamos um
Nothing. No caso de sucesso, pousamos pássaros na direita e
então fazemos a mesma coisa tudo de novo. Converter essa monstruosidade
em uma cadeia organizada de aplicações monadic com
>>= é um exemplo clássico de como a Monad
Maybe nos poupa muito tempo quando temos que fazer
sucessivamente computações que são baseadas em computações que podem ter
falhado.
Observe como a implementação Maybe de
>>= apresenta exatamente essa lógica de ver se um
valor é Nothing e, se for, retornar um Nothing
imediatamente e, se não for, seguir em frente com o que está dentro do
Just.
Nesta seção, pegamos algumas funções que tínhamos e vimos que elas
funcionariam melhor se os valores que retornassem suportassem falha. Ao
transformar esses valores em valores Maybe e substituir a
aplicação normal de função por >>=, obtivemos um
mecanismo para lidar com falhas praticamente de graça, porque
>>= deve preservar o contexto do valor ao qual aplica
funções. Neste caso, o contexto era que nossos valores eram valores com
falha e, portanto, quando aplicamos funções a tais valores, a
possibilidade de falha sempre foi levada em conta.
do notation
Monads em Haskell são tão úteis que ganharam sua própria sintaxe
especial chamada do notation. Já encontramos a
do notation quando estávamos fazendo E/S e lá dissemos que
era para colar várias ações de E/S em uma. Bem, como se vê, a
do notation não é apenas para IO, mas pode ser
usada para qualquer Monad. Seu princípio ainda é o mesmo: colar monadic
values em sequência. Vamos dar uma olhada em como a
do notation funciona e por que é útil.
Considere este exemplo familiar de aplicação monadic:
ghci> Just 3 >>= (\x -> Just (show x ++ "!"))
Just "3!"Já vimos isso. Alimentar um monadic value a uma função que retorna
um, nada demais. Observe como quando fazemos isso, x se
torna 3 dentro do lambda. Uma vez que estamos dentro desse
lambda, é apenas um valor normal, em vez de um monadic value. Agora, e
se tivéssemos outro >>= dentro dessa função? Confira
isso:
ghci> Just 3 >>= (\x -> Just "!" >>= (\y -> Just (show x ++ y)))
Just "3!"Ah, um uso aninhado de >>=! No lambda mais
externo, alimentamos Just "!" ao lambda
\y -> Just (show x ++ y). Dentro deste lambda, o
y se torna "!". x ainda é
3 porque o obtivemos do lambda externo. Tudo isso meio que
me lembra a seguinte expressão:
ghci> let x = 3; y = "!" in show x ++ y
"3!"A principal diferença entre esses dois é que os valores no primeiro exemplo são monadic. Eles são valores com um contexto de falha. Podemos substituir qualquer um deles por uma falha:
ghci> Nothing >>= (\x -> Just "!" >>= (\y -> Just (show x ++ y)))
Nothing
ghci> Just 3 >>= (\x -> Nothing >>= (\y -> Just (show x ++ y)))
Nothing
ghci> Just 3 >>= (\x -> Just "!" >>= (\y -> Nothing))
NothingNa primeira linha, alimentar um Nothing a uma função
naturalmente resulta em um Nothing. Na segunda linha,
alimentamos Just 3 a uma função e o x se torna
3, mas então alimentamos um Nothing ao lambda
interno e o resultado disso é Nothing, o que faz com que o
lambda externo produza Nothing também. Então isso é meio
como atribuir valores a variáveis em expressões let, só que
os valores em questão são monadic values.
Para ilustrar ainda mais esse ponto, vamos escrever isso em um script
e fazer com que cada valor Maybe ocupe sua própria
linha:
foo :: Maybe String
foo = Just 3 >>= (\x ->
Just "!" >>= (\y ->
Just (show x ++ y)))Para nos salvar de escrever todos esses lambdas irritantes, Haskell
nos dá a do notation. Ela nos permite escrever o pedaço de
código anterior assim:
foo :: Maybe String
foo = do
x <- Just 3
y <- Just "!"
Just (show x ++ y)
Parece que ganhamos a capacidade de extrair temporariamente coisas de
valores Maybe sem ter que verificar se os valores
Maybe são valores Just ou valores
Nothing a cada passo. Que legal! Se algum dos valores dos
quais tentamos extrair for Nothing, toda a expressão
do resultará em um Nothing. Estamos arrancando
seus valores (possivelmente existentes) e deixando
>>= se preocupar com o contexto que vem com esses
valores. É importante lembrar que do expressions são apenas
uma sintaxe diferente para encadear monadic values.
Em uma do expression, cada linha é um monadic value.
Para inspecionar seu resultado, usamos <-. Se tivermos
um Maybe String e o vincularmos com <- a
uma variável, essa variável será uma String, assim como
quando usamos >>= para alimentar monadic values a
lambdas. O último monadic value em uma do expression, como
Just (show x ++ y) aqui, não pode ser usado com
<- para vincular seu resultado, porque isso não faria
sentido se traduzíssemos a do expression de volta para uma
cadeia de aplicações >>=. Em vez disso, seu resultado
é o resultado de todo o monadic value colado, levando em consideração a
possível falha de quaisquer anteriores.
Por exemplo, examine a seguinte linha:
ghci> Just 9 >>= (\x -> Just (x > 8))
Just TrueComo o parâmetro esquerdo de >>= é um valor
Just, o lambda é aplicado a 9 e o resultado é
um Just True. Se reescrevermos isso em notação
do, obtemos:
marySue :: Maybe Bool
marySue = do
x <- Just 9
Just (x > 8)Se compararmos esses dois, é fácil ver por que o resultado de todo o
monadic value é o resultado do último monadic value na do
expression com todos os anteriores encadeados nele.
A rotina de nosso equilibrista também pode ser expressa com a
do notation. landLeft e landRight
pegam um número de pássaros e uma vara e produzem uma vara embrulhada em
um Just, a menos que o equilibrista escorregue, caso em que
um Nothing é produzido. Usamos >>= para
encadear etapas sucessivas porque cada uma dependia da anterior e cada
uma tinha um contexto adicionado de possível falha. Aqui estão dois
pássaros pousando no lado esquerdo, depois dois pássaros pousando no
lado direito e depois um pássaro pousando no lado esquerdo:
routine :: Maybe Pole
routine = do
start <- return (0,0)
first <- landLeft 2 start
second <- landRight 2 first
landLeft 1 secondVamos ver se ele tem sucesso:
ghci> routine
Just (3,2)Ele tem! Ótimo. Quando estávamos fazendo essas rotinas escrevendo
explicitamente >>=, geralmente dizíamos algo como
return (0,0) >>= landLeft 2, porque
landLeft 2 é uma função que retorna um valor
Maybe. Com do expressions, no entanto, cada
linha deve apresentar um monadic value. Então passamos explicitamente a
Pole anterior para as funções landLeft
landRight. Se examinássemos as variáveis às quais
vinculamos nossos valores Maybe, start seria
(0,0), first seria (2,0) e assim
por diante.
Como do expressions são escritas linha por linha, elas
podem parecer código imperativo para algumas pessoas. Mas a coisa é,
elas são apenas sequenciais, pois cada valor em cada linha depende do
resultado dos anteriores, juntamente com seus contextos (neste caso, se
tiveram sucesso ou falharam).
Novamente, vamos dar uma olhada em como este trecho de código seria
se não tivéssemos usado os aspectos monadic de Maybe:
routine :: Maybe Pole
routine =
case Just (0,0) of
Nothing -> Nothing
Just start -> case landLeft 2 start of
Nothing -> Nothing
Just first -> case landRight 2 first of
Nothing -> Nothing
Just second -> landLeft 1 secondVeja como no caso de sucesso, a tupla dentro de
Just (0,0) se torna start, o resultado de
landLeft 2 start se torna first, etc.
Se quisermos jogar uma casca de banana para Pierre na
do notation, podemos fazer o seguinte:
routine :: Maybe Pole
routine = do
start <- return (0,0)
first <- landLeft 2 start
Nothing
second <- landRight 2 first
landLeft 1 secondQuando escrevemos uma linha na do notation sem vincular
o monadic value com <-, é exatamente como colocar
>> após o monadic value cujo resultado queremos
ignorar. Nós sequenciamos o monadic value, mas ignoramos seu resultado
porque não nos importamos com o que ele é e é mais bonito do que
escrever _ <- Nothing, que é equivalente ao acima.
Quando usar a do notation e quando usar explicitamente
>>= depende de você. Acho que este exemplo se presta
a escrever explicitamente >>= porque cada etapa
depende especificamente do resultado da anterior. Com a
do notation, tivemos que escrever especificamente em qual
vara os pássaros estão pousando, mas toda vez usamos aquela que veio
logo antes. Mas ainda assim, isso nos deu alguma visão sobre a
do notation.
Na do notation, quando vinculamos monadic values a
nomes, podemos utilizar pattern matching, assim como em expressões
let e parâmetros de função. Aqui está um exemplo de pattern
matching em uma do notation:
justH :: Maybe Char
justH = do
(x:xs) <- Just "hello"
return xUsamos pattern matching para pegar o primeiro caractere da string
"hello" e então o apresentamos como resultado. Então
justH avalia para Just 'h'.
E se esse pattern matching falhasse? Quando o pattern matching em uma
função falha, o próximo padrão é correspondido. Se a correspondência
cair através de todos os padrões para uma determinada função, um erro é
lançado e nosso programa trava. Por outro lado, pattern matching falho
em expressões let resulta em um erro sendo produzido
imediatamente, porque o mecanismo de cair através de padrões não está
presente em expressões let. Quando o pattern matching falha
em uma do expression, a função fail é chamada.
Ela faz parte da typeclass Monad e permite que o pattern
matching falho resulte em uma falha no contexto da Monad atual em vez de
fazer nosso programa travar. Sua implementação padrão é esta:
fail :: (Monad m) => String -> m a
fail msg = error msgEntão, por padrão, ela faz nosso programa travar, mas Monads que
incorporam um contexto de possível falha (como Maybe)
geralmente a implementam por conta própria. Para Maybe, ela
é implementada assim:
fail _ = NothingEla ignora a mensagem de erro e faz um Nothing. Então,
quando o pattern matching falha em um valor Maybe que está
escrito na notação do, todo o valor resulta em um
Nothing. Isso é preferível a ter nosso programa travando.
Aqui está uma expressão do com um padrão que está fadado a
falhar:
wopwop :: Maybe Char
wopwop = do
(x:xs) <- Just ""
return xO pattern matching falha, então o efeito é o mesmo que se toda a
linha com o padrão fosse substituída por um Nothing. Vamos
testar isso:
ghci> wopwop
NothingO pattern matching falho causou uma falha dentro do contexto de nossa Monad em vez de causar uma falha em todo o programa, o que é bem legal.
The List Monad

Até agora, vimos como valores Maybe podem ser vistos
como valores com um contexto de falha e como podemos incorporar
tratamento de falha em nosso código usando >>= para
alimentá-los a funções. Nesta seção, vamos dar uma olhada em como usar
os aspectos monadic de listas para trazer não-determinismo ao nosso
código de uma maneira clara e legível.
Já falamos sobre como listas representam valores não-determinísticos
quando são usadas como Applicatives. Um valor como 5 é
determinístico. Ele tem apenas um resultado e sabemos exatamente o que
é. Por outro lado, um valor como [3,8,9] contém vários
resultados, então podemos vê-lo como um valor que é na verdade muitos
valores ao mesmo tempo. Usar listas como Applicative Functors mostra bem
esse não-determinismo:
ghci> (*) <$> [1,2,3] <*> [10,100,1000]
[10,100,1000,20,200,2000,30,300,3000]Todas as combinações possíveis de multiplicar elementos da lista da esquerda com elementos da lista da direita estão incluídas na lista resultante. Ao lidar com não-determinismo, há muitas escolhas que podemos fazer, então apenas tentamos todas elas, e assim o resultado é um valor não-determinístico também, só que tem muito mais resultados.
Esse contexto de não-determinismo se traduz para Monads muito bem.
Vamos em frente e ver como a instância Monad para listas se
parece:
instance Monad [] where
return x = [x]
xs >>= f = concat (map f xs)
fail _ = []return faz a mesma coisa que pure, então já
devemos estar familiarizados com return para listas. Ele
pega um valor e o coloca em um contexto padrão mínimo que ainda produz
esse valor. Em outras palavras, ele faz uma lista que tem apenas aquele
valor como resultado. Isso é útil para quando queremos apenas embrulhar
um valor normal em uma lista para que ele possa interagir com valores
não-determinísticos.
Para entender como >>= funciona para listas, é
melhor se dermos uma olhada nele em ação para ganhar alguma intuição
primeiro. >>= é sobre pegar um valor com um contexto
(um monadic value) e alimentá-lo a uma função que pega um valor normal e
retorna um que tem contexto. Se essa função produzisse apenas um valor
normal em vez de um com contexto, >>= não seria tão
útil porque após um uso, o contexto seria perdido. De qualquer forma,
vamos tentar alimentar um valor não-determinístico a uma função:
ghci> [3,4,5] >>= \x -> [x,-x]
[3,-3,4,-4,5,-5]Quando usamos >>= com Maybe, o
monadic value foi alimentado na função enquanto cuidava de possíveis
falhas. Aqui, ele cuida do não-determinismo para nós.
[3,4,5] é um valor não-determinístico e o alimentamos em
uma função que retorna um valor não-determinístico também. O resultado
também é não-determinístico, e apresenta todos os resultados possíveis
de pegar elementos da lista [3,4,5] e passá-los para a
função \x -> [x,-x]. Essa função pega um número e produz
dois resultados: um negado e um que não muda. Então, quando usamos
>>= para alimentar essa lista à função, cada número é
negado e também mantido inalterado. O x do lambda assume
cada valor da lista que é alimentado a ele.
Para ver como isso é alcançado, podemos apenas seguir a
implementação. Primeiro, começamos com a lista [3,4,5].
Então, mapeamos o lambda sobre ela e o resultado é o seguinte:
[[3,-3],[4,-4],[5,-5]]O lambda é aplicado a cada elemento e obtemos uma lista de listas. Finalmente, nós apenas achatamos (flatten) a lista e voilà! Aplicamos uma função não-determinística a um valor não-determinístico!
O não-determinismo também inclui suporte para falha. A lista vazia
[] é praticamente o equivalente a Nothing,
porque significa a ausência de um resultado. É por isso que a falha é
apenas definida como a lista vazia. A mensagem de erro é jogada fora.
Vamos brincar com listas que falham:
ghci> [] >>= \x -> ["bad","mad","rad"]
[]
ghci> [1,2,3] >>= \x -> []
[]Na primeira linha, uma lista vazia é alimentada ao lambda. Como a
lista não tem elementos, nenhum deles pode ser passado para a função e,
portanto, o resultado é uma lista vazia. Isso é semelhante a alimentar
Nothing a uma função.
Na segunda linha, cada elemento é passado para a função, mas o elemento é ignorado e a função apenas retorna uma lista vazia. Como a função falha para cada elemento que entra nela, o resultado é uma falha.
Assim como com valores Maybe, podemos encadear várias
listas com >>=, propagando o não-determinismo:
ghci> [1,2] >>= \n -> ['a','b'] >>= \ch -> return (n,ch)
[(1,'a'),(1,'b'),(2,'a'),(2,'b')]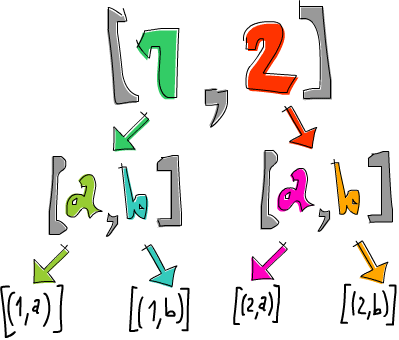
A lista [1,2] é vinculada a n e
['a','b'] é vinculada a ch. Então, fazemos
return (n,ch) (ou [(n,ch)]), o que significa
pegar um par de (n,ch) e colocá-lo em um contexto mínimo
padrão. Neste caso, é fazer a menor lista possível que ainda apresenta
(n,ch) como resultado e apresenta o mínimo de
não-determinismo possível. Seu efeito no contexto é mínimo. O que
estamos dizendo aqui é o seguinte: para cada elemento em
[1,2], percorra cada elemento em ['a','b'] e
produza uma tupla de um elemento de cada lista.
De um modo geral, como return pega um valor e o envolve
em um contexto mínimo, ele não tem nenhum efeito extra (como falhar em
Maybe ou resultar em mais não-determinismo para listas),
mas apresenta algo como seu resultado.
Quando você tem valores não-determinísticos interagindo, você pode ver sua computação como uma árvore onde cada resultado possível em uma lista representa um ramo separado.
Aqui está a expressão anterior reescrita na
do notation:
listOfTuples :: [(Int,Char)]
listOfTuples = do
n <- [1,2]
ch <- ['a','b']
return (n,ch)Isso torna um pouco mais óbvio que n assume cada valor
de [1,2] e ch assume cada valor de
['a','b']. Assim como com Maybe, estamos
extraindo os elementos dos monadic values e tratando-os como valores
normais e >>= cuida do contexto para nós. O contexto
neste caso é o não-determinismo.
Usar listas com do notation realmente me lembra de algo
que vimos antes. Confira o seguinte trecho de código:
ghci> [ (n,ch) | n <- [1,2], ch <- ['a','b'] ]
[(1,'a'),(1,'b'),(2,'a'),(2,'b')]Sim! List comprehensions! Em nosso exemplo de
do notation, n tornou-se cada resultado de
[1,2] e para cada resultado, ch recebeu um
resultado de ['a','b'] e então a linha final colocou
(n,ch) em um contexto padrão (uma lista unitária) para
apresentá-lo como o resultado sem introduzir qualquer não-determinismo
adicional. Nesta list comprehension, a mesma coisa aconteceu, só que não
tivemos que escrever return no final para apresentar
(n,ch) como o resultado porque a parte de saída de uma list
comprehension fez isso por nós.
De fato, list comprehensions são apenas syntactic sugar para usar
listas como Monads. No final, list comprehensions e listas em
do notation se traduzem em usar >>= para
fazer computações que apresentam não-determinismo.
List comprehensions nos permitem filtrar nossa saída. Por exemplo,
podemos filtrar uma lista de números para procurar apenas aqueles
números cujos dígitos contêm um 7:
ghci> [ x | x <- [1..50], '7' `elem` show x ]
[7,17,27,37,47]Aplicamos show a x para transformar nosso
número em uma string e então verificamos se o caractere '7'
faz parte dessa string. Muito inteligente. Para ver como a filtragem em
list comprehensions se traduz para a List Monad, temos que verificar a
função guard e a typeclass MonadPlus. A
typeclass MonadPlus é para Monads que também podem agir
como Monoids. Aqui está sua definição:
class Monad m => MonadPlus m where
mzero :: m a
mplus :: m a -> m a -> m amzero é sinônimo de mempty da typeclass
Monoid e mplus corresponde a
mappend. Como listas são Monoids, bem como Monads, elas
podem ser feitas uma instância desta typeclass:
instance MonadPlus [] where
mzero = []
mplus = (++)Para listas mzero representa uma computação
não-determinística que não tem resultados de forma alguma — uma
computação falha. mplus une dois valores
não-determinísticos em um. A função guard é definida
assim:
guard :: (MonadPlus m) => Bool -> m ()
guard True = return ()
guard False = mzeroEla pega um valor booleano e se for True, pega um
() e o coloca em um contexto padrão mínimo que ainda tem
sucesso. Caso contrário, ela faz um monadic value de falha. Aqui está
ela em ação:
ghci> guard (5 > 2) :: Maybe ()
Just ()
ghci> guard (1 > 2) :: Maybe ()
Nothing
ghci> guard (5 > 2) :: [()]
[()]
ghci> guard (1 > 2) :: [()]
[]Parece interessante, mas como é útil? Na List Monad, nós a usamos para filtrar computações não-determinísticas. Observe:
ghci> [1..50] >>= (\x -> guard ('7' `elem` show x) >> return x)
[7,17,27,37,47]O resultado aqui é o mesmo que o resultado de nossa compreensão de
lista anterior. Como guard consegue isso? Vamos ver
primeiro como guard funciona em conjunto com
>>:
ghci> guard (5 > 2) >> return "cool" :: [String]
["cool"]
ghci> guard (1 > 2) >> return "cool" :: [String]
[]Se guard tiver sucesso, o resultado contido nele é uma
tupla vazia. Então, usamos >> para ignorar essa tupla
vazia e apresentar outra coisa como resultado. No entanto, se
guard falhar, então o return posterior também
falhará, porque alimentar uma lista vazia a uma função com
>>= sempre resulta em uma lista vazia. Um
guard basicamente diz: se este booleano for
False, então produza uma falha aqui mesmo, caso contrário,
faça um valor bem-sucedido que tenha um resultado fictício de
() dentro dele. Tudo o que isso faz é permitir que a
computação continue.
Aqui está o exemplo anterior reescrito na
do notation:
sevensOnly :: [Int]
sevensOnly = do
x <- [1..50]
guard ('7' `elem` show x)
return xSe tivéssemos esquecido de apresentar x como o resultado
final usando return, a lista resultante seria apenas uma
lista de tuplas vazias. Aqui está isso novamente na forma de uma list
comprehension:
ghci> [ x | x <- [1..50], '7' `elem` show x ]
[7,17,27,37,47]Portanto, a filtragem em list comprehensions é o mesmo que usar
guard.
A missão do cavalo
Aqui está um problema que realmente se presta a ser resolvido com não-determinismo. Digamos que você tenha um tabuleiro de xadrez e apenas uma peça de cavalo nele. Queremos descobrir se o cavalo pode chegar a uma determinada posição em três movimentos. Vamos usar apenas um par de números para representar a posição do cavalo no tabuleiro de xadrez. O primeiro número determinará a coluna em que ele está e o segundo número determinará a linha.
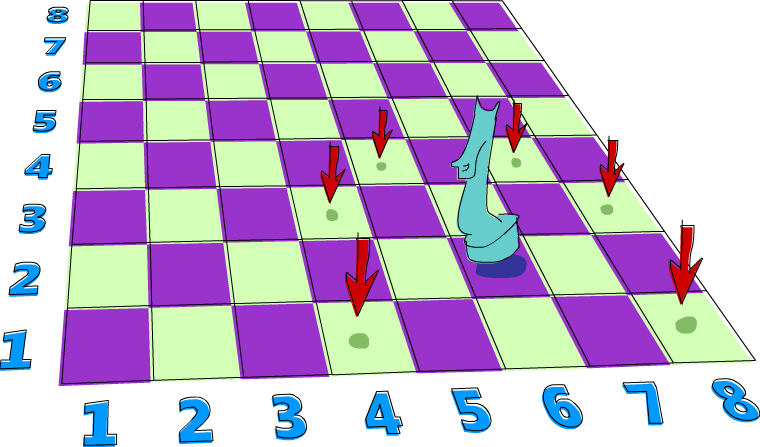
Vamos criar um sinônimo de tipo para a posição atual do cavalo no tabuleiro de xadrez:
type KnightPos = (Int,Int)Então, digamos que o cavalo comece em (6,2). Ele pode
chegar a (6,1) em exatamente três movimentos? Vamos ver. Se
começarmos em (6,2), qual é o melhor movimento a fazer a
seguir? Eu sei, que tal todos eles! Temos não-determinismo à nossa
disposição, então, em vez de escolher um movimento, vamos escolher todos
eles de uma vez. Aqui está uma função que pega a posição do cavalo e
retorna todos os seus próximos movimentos:
moveKnight :: KnightPos -> [KnightPos]
moveKnight (c,r) = do
(c',r') <- [(c+2,r-1),(c+2,r+1),(c-2,r-1),(c-2,r+1)
,(c+1,r-2),(c+1,r+2),(c-1,r-2),(c-1,r+2)
]
guard (c' `elem` [1..8] && r' `elem` [1..8])
return (c',r')O cavalo sempre pode dar um passo horizontalmente ou verticalmente e
dois passos horizontalmente ou verticalmente, mas seu movimento deve ser
tanto horizontal quanto vertical. (c',r') assume cada valor
da lista de movimentos e então guard garante que o novo
movimento, (c',r'), ainda esteja no tabuleiro. Se não
estiver, ele produz uma lista vazia, o que causa uma falha e
return (c',r') não é executado para essa posição.
Esta função também pode ser escrita sem o uso de listas como uma
Monad, mas fizemos isso aqui apenas por diversão. Aqui está a mesma
função feita com filter:
moveKnight :: KnightPos -> [KnightPos]
moveKnight (c,r) = filter onBoard
[(c+2,r-1),(c+2,r+1),(c-2,r-1),(c-2,r+1)
,(c+1,r-2),(c+1,r+2),(c-1,r-2),(c-1,r+2)
]
where onBoard (c,r) = c `elem` [1..8] && r `elem` [1..8]Ambas fazem a mesma coisa, então escolha a que você acha mais bonita. Vamos testar:
ghci> moveKnight (6,2)
[(8,1),(8,3),(4,1),(4,3),(7,4),(5,4)]
ghci> moveKnight (8,1)
[(6,2),(7,3)]Funciona que é uma beleza! Pegamos uma posição e realizamos todos os
movimentos possíveis de uma vez, por assim dizer. Então, agora que temos
uma próxima posição não-determinística, apenas usamos
>>= para alimentá-la a moveKnight. Aqui
está uma função que pega uma posição e retorna todas as posições que
você pode alcançar a partir dela em três movimentos:
in3 :: KnightPos -> [KnightPos]
in3 start = do
first <- moveKnight start
second <- moveKnight first
moveKnight secondSe você passar (6,2), a lista resultante é bem grande,
porque se houver várias maneiras de chegar a alguma posição em três
movimentos, ela aparece na lista várias vezes. O exemplo acima sem a
do notation:
in3 start = return start >>= moveKnight >>= moveKnight >>= moveKnightUsar >>= uma vez nos dá todos os movimentos
possíveis desde o início e então, quando usamos >>=
pela segunda vez, para cada primeiro movimento possível, cada próximo
movimento possível é computado, e o mesmo vale para o último
movimento.
Colocar um valor em um contexto padrão aplicando return
a ele e depois alimentá-lo para uma função com >>= é
o mesmo que apenas aplicar normalmente a função a esse valor, mas
fizemos isso aqui de qualquer maneira por estilo.
Agora, vamos fazer uma função que pega duas posições e nos diz se você pode ir de uma para a outra em exatamente três passos:
canReachIn3 :: KnightPos -> KnightPos -> Bool
canReachIn3 start end = end `elem` in3 startGeramos todas as posições possíveis em três passos e então vemos se a
posição que estamos procurando está entre elas. Então vamos ver se
podemos ir de (6,2) para (6,1) em três
movimentos:
ghci> (6,2) `canReachIn3` (6,1)
TrueSim! Que tal de (6,2) para (7,3)?
ghci> (6,2) `canReachIn3` (7,3)
FalseNão! Como exercício, você pode alterar essa função para que, quando você puder alcançar uma posição a partir da outra, ela diga quais movimentos tomar. Mais tarde, veremos como modificar essa função para que também passemos o número de movimentos a serem feitos, em vez de esse número ser codificado como é agora.
Monad Laws

Assim como Applicative Functors, e Functors antes deles, Monads vêm
com algumas leis que todas as instâncias de Monads devem respeitar. Só
porque algo é feito uma instância da typeclass Monad não
significa que é uma Monad, significa apenas que foi feito uma instância
de uma typeclass. Para que um tipo seja verdadeiramente uma Monad, as
Monad laws devem valer para esse tipo. Essas leis nos permitem fazer
suposições razoáveis sobre o tipo e seu comportamento.
Haskell permite que qualquer tipo seja uma instância de qualquer
typeclass, desde que os tipos verifiquem. Ele não pode verificar se as
Monad laws valem para um tipo, no entanto, então, se estamos fazendo uma
nova instância da typeclass Monad, temos que estar
razoavelmente certos de que tudo está bem com as Monad laws para esse
tipo. Podemos confiar nos tipos que vêm com a biblioteca padrão para
satisfazer as laws, mas mais tarde, quando formos fazer nossas próprias
Monads, teremos que verificar manualmente se as laws valem. Mas não se
preocupe, elas não são complicadas.
Left Identity
A primeira Monad law afirma que se pegarmos um valor, o colocarmos em
um contexto padrão com return e então o alimentarmos a uma
função usando >>=, é o mesmo que apenas pegar o valor
e aplicar a função a ele. Para colocar formalmente:
return x >>= fé a mesma maldita coisa quef x
Se você olhar para monadic values como valores com um contexto e
return como pegar um valor e colocá-lo em um contexto
mínimo padrão que ainda apresenta esse valor como seu resultado, faz
sentido, porque se esse contexto é realmente mínimo, alimentar esse
monadic value a uma função não deve ser muito diferente de apenas
aplicar a função ao valor normal, e de fato não é diferente de forma
alguma.
Para a Maybe Monad, return é definida como
Just. A Maybe Monad é toda sobre possível falha, e se temos
um valor e queremos colocá-lo em tal contexto, faz sentido que o
tratemos como uma computação bem-sucedida porque, bem, sabemos qual é o
valor. Aqui está algum uso de return com
Maybe:
ghci> return 3 >>= (\x -> Just (x+100000))
Just 100003
ghci> (\x -> Just (x+100000)) 3
Just 100003Para a List Monad, return coloca algo em uma lista
unitária. A implementação de >>= para listas percorre
todos os valores na lista e aplica a função a eles, mas como há apenas
um valor em uma lista unitária, é o mesmo que aplicar a função a esse
valor:
ghci> return "WoM" >>= (\x -> [x,x,x])
["WoM","WoM","WoM"]
ghci> (\x -> [x,x,x]) "WoM"
["WoM","WoM","WoM"]Dissemos que para IO, usar return faz uma
ação de E/S que não tem efeitos colaterais, mas apenas apresenta um
valor como seu resultado. Então faz sentido que essa lei valha para
IO também.
Right Identity
A segunda lei afirma que se temos um monadic value e usamos
>>= para alimentá-lo a return, o
resultado é nosso monadic value original. Formalmente:
m >>= returnnão é diferente de apenasm
Esta pode ser um pouco menos óbvia que a primeira, mas vamos ver por
que ela deve valer. Quando alimentamos monadic values a funções usando
>>=, essas funções pegam valores normais e retornam
monadic values. return é uma dessas funções, se você
considerar seu tipo. Como dissemos, return coloca um valor
em um contexto mínimo que ainda apresenta esse valor como seu resultado.
Isso significa que, por exemplo, para Maybe, ele não
introduz nenhuma falha e para listas, ele não introduz nenhum
não-determinismo extra. Aqui está um teste para algumas Monads:
ghci> Just "move on up" >>= (\x -> return x)
Just "move on up"
ghci> [1,2,3,4] >>= (\x -> return x)
[1,2,3,4]
ghci> putStrLn "Wah!" >>= (\x -> return x)
Wah!Se olharmos mais de perto o exemplo da lista, a implementação de
>>= é:
xs >>= f = concat (map f xs)Então, quando alimentamos [1,2,3,4] a
return, primeiro return é mapeado sobre
[1,2,3,4], resultando em [[1],[2],[3],[4]] e
então isso é concatenado e temos nossa lista original.
A identidade à esquerda e a identidade à direita são basicamente leis
que descrevem como return deve se comportar. É uma função
importante para transformar valores normais em monadic values e não
seria bom se o monadic value que ela produzisse fizesse um monte de
outras coisas.
Associativity
A final Monad law diz que quando temos uma cadeia de aplicações de
funções monadic com >>=, não deve importar como elas
são aninhadas. Escrito formalmente:
- Fazer
(m >>= f) >>= gé exatamente como fazerm >>= (\x -> f x >>= g)
Hmmm, agora o que está acontecendo aqui? Temos um monadic value
m e duas monadic functions f e g.
Quando estamos fazendo (m >>= f) >>= g, estamos
alimentando m a f, o que resulta em um monadic
value. Então, alimentamos esse monadic value a g. Na
expressão m >>= (\x -> f x >>= g), pegamos
um monadic value e o alimentamos a uma função que alimenta o resultado
de f x a g. Não é fácil ver como esses dois
são iguais, então vamos dar uma olhada em um exemplo que torna essa
igualdade um pouco mais clara.
Lembra quando tivemos nosso equilibrista Pierre andando na corda bamba enquanto pássaros pousavam em sua vara de equilíbrio? Para simular pássaros pousando em sua vara de equilíbrio, fizemos uma cadeia de várias funções que poderiam produzir falha:
ghci> return (0,0) >>= landRight 2 >>= landLeft 2 >>= landRight 2
Just (2,4)Começamos com Just (0,0) e então vinculamos esse valor à
próxima monadic function, landRight 2. O resultado disso
foi outro monadic value que foi vinculado à próxima monadic function, e
assim por diante. Se fôssemos colocar parênteses explicitamente nisso,
escreveríamos:
ghci> ((return (0,0) >>= landRight 2) >>= landLeft 2) >>= landRight 2
Just (2,4)Mas também podemos escrever a rotina assim:
return (0,0) >>= (\x ->
landRight 2 x >>= (\y ->
landLeft 2 y >>= (\z ->
landRight 2 z)))return (0,0) é o mesmo que Just (0,0) e
quando o alimentamos para o lambda, o x se torna
(0,0). landRight pega um número de pássaros e
uma vara (uma tupla de números) e é isso que é passado. Isso resulta em
um Just (0,2) e quando alimentamos isso para o próximo
lambda, y é (0,2). Isso continua até que o
pouso final do pássaro produza um Just (2,4), que é de fato
o resultado de toda a expressão.
Então não importa como você aninha a alimentação de valores para
monadic functions, o que importa é o significado delas. Aqui está outra
maneira de ver esta lei: considere compor duas funções, f e
g. A composição de duas funções é implementada assim:
(.) :: (b -> c) -> (a -> b) -> (a -> c)
f . g = (\x -> f (g x))Se o tipo de g for a -> b e o tipo de
f for b -> c, nós as organizamos em uma
nova função que tem um tipo de a -> c, para que seu
parâmetro seja passado entre essas funções. Agora, e se essas duas
funções fossem monadic, ou seja, e se os valores que elas retornassem
fossem monadic values? Se tivéssemos uma função do tipo
a -> m b, não poderíamos simplesmente passar seu
resultado para uma função do tipo b -> m c, porque essa
função aceita um b normal, não um monadic. No entanto,
poderíamos usar >>= para fazer isso acontecer. Então,
usando >>=, podemos compor duas monadic
functions:
(<=<) :: (Monad m) => (b -> m c) -> (a -> m b) -> (a -> m c)
f <=< g = (\x -> g x >>= f)Então agora podemos compor duas monadic functions:
ghci> let f x = [x,-x]
ghci> let g x = [x*3,x*2]
ghci> let h = f <=< g
ghci> h 3
[9,-9,6,-6]Legal. Então o que isso tem a ver com a lei da associatividade? Bem,
quando olhamos para a lei como uma lei de composições, ela afirma que
f <=< (g <=< h) deve ser o
mesmo que (f <=< g) <=< h.
Esta é apenas outra maneira de dizer que para Monads, o aninhamento de
operações não deve importar.
Se traduzirmos as duas primeiras leis para usar
<=<, então a Left Identity afirma que para toda
monadic function f, f <=< return é o mesmo que escrever
apenas f e a Right Identity diz que return <=< f também não é diferente de
f.
Isso é muito semelhante a como, se f é uma função
normal, (f . g) . h é o mesmo que f . (g . h),
f . id é sempre o mesmo que f e
id . f também é apenas f.
Neste capítulo, demos uma olhada no básico das Monads e aprendemos como a Maybe Monad e a List Monad funcionam. No próximo capítulo, daremos uma olhada em um monte de outras Monads legais e também aprenderemos como fazer as nossas próprias.