Recursão (Recursion)
Olá recursão! (Hello recursion!)

Mencionamos brevemente a recursão no capítulo anterior. Neste capítulo, examinaremos mais de perto a recursão, por que ela é importante para o Haskell e como podemos elaborar soluções muito concisas e elegantes para problemas pensando recursivamente.
Se você ainda não sabe o que é recursão, leia esta frase. Haha! Brincadeirinha! A recursão é na verdade uma maneira de definir funções nas quais a função é aplicada dentro de sua própria definição. As definições em matemática são frequentemente dadas recursivamente. Por exemplo, a sequência de fibonacci é definida recursivamente. Primeiro, definimos os dois primeiros números de fibonacci não recursivamente. Dizemos que F(0) = 0 e F(1) = 1, o que significa que os 0-ésimo e 1-ésimo números de fibonacci são 0 e 1, respectivamente. Então dizemos que, para qualquer outro número natural, esse número de fibonacci é a soma dos dois números de fibonacci anteriores. Então F(n) = F(n-1) + F(n-2). Dessa forma, F(3) é F(2) + F(1), que é (F(1) + F(0)) + F(1). Como agora chegamos apenas aos números de fibonacci definidos não recursivamente, podemos dizer com segurança que F(3) é 2. Ter um elemento ou dois em uma definição de recursão definidos não recursivamente (como F(0) e F(1) aqui) também é chamado de condição de borda (edge condition) e é importante se você deseja que sua função recursiva termine. Se não tivéssemos definido F(0) e F(1) não recursivamente, você nunca obteria uma solução para qualquer número, pois chegaria a 0 e depois entraria em números negativos. De repente, você estaria dizendo que F(-2000) é F(-2001) + F(-2002) e ainda não haveria um fim à vista!
A recursão é importante para o Haskell porque, ao contrário das linguagens imperativas, você faz cálculos em Haskell declarando o que algo é em vez de declarar como obtê-lo. É por isso que não há loops while ou for em Haskell e, em vez disso, muitas vezes temos que usar recursão para declarar o que algo é.
Incrível máximo (Maximum awesome)
A função maximum pega uma lista de coisas que podem ser
ordenadas (por exemplo, instâncias da typeclass Ord) e
retorna a maior delas. Pense em como você implementaria isso de maneira
imperativa. Você provavelmente configuraria uma variável para conter o
valor máximo até o momento e, em seguida, percorreria os elementos de
uma lista e, se um elemento fosse maior do que o valor máximo atual,
você o substituiria por esse elemento. O valor máximo que permanece no
final é o resultado. Ufa! São muitas palavras para descrever um
algoritmo tão simples!
Agora vamos ver como o definiríamos recursivamente. Poderíamos primeiro estabelecer uma condição de borda e dizer que o máximo de uma lista singleton é igual ao único elemento nela. Então podemos dizer que o máximo de uma lista mais longa é a cabeça se a cabeça for maior que o máximo da cauda. Se o máximo da cauda for maior, bem, então é o máximo da cauda. É isso! Agora vamos implementar isso em Haskell.
maximum' :: (Ord a) => [a] -> a
maximum' [] = error "maximum of empty list"
maximum' [x] = x
maximum' (x:xs)
| x > maxTail = x
| otherwise = maxTail
where maxTail = maximum' xsComo você pode ver, o pattern matching combina muito bem com a recursão! A maioria das linguagens imperativas não tem pattern matching, então você precisa fazer muitas instruções if else para testar as condições de borda. Aqui, simplesmente as colocamos como padrões. Portanto, a primeira condição de borda diz que, se a lista estiver vazia, falhe! Faz sentido porque qual é o máximo de uma lista vazia? Eu não sei. O segundo padrão também estabelece uma condição de borda. Ele diz que, se for a lista singleton, apenas devolva o único elemento.
Agora, o terceiro padrão é onde a ação acontece. Usamos pattern
matching para dividir uma lista em cabeça e cauda. Este é um idioma
muito comum ao fazer recursão com listas, então acostume-se. Usamos uma
ligação where para definir maxTail como o máximo
do restante da lista. Em seguida, verificamos se a cabeça é maior que o
máximo do restante da lista. Se for, retornamos a cabeça. Caso
contrário, retornamos o máximo do restante da lista.
Vamos pegar uma lista de números de exemplo e verificar como isso
funcionaria neles: [2,5,1]. Se chamarmos
maximum' nisso, os dois primeiros padrões não
corresponderão. O terceiro corresponderá e a lista será dividida em
2 e [5,1]. A cláusula where quer
saber o máximo de [5,1], então seguimos esse caminho. Ele
corresponde ao terceiro padrão novamente e [5,1] é dividido
em 5 e [1]. Novamente, a cláusula
where quer saber o máximo de [1]. Como essa é
a condição de borda, ela retorna 1. Finalmente! Então,
subindo um degrau, comparando 5 com o máximo de
[1] (que é 1), obviamente obtemos
5. Portanto, agora sabemos que o máximo de
[5,1] é 5. Subimos um degrau novamente onde
tínhamos 2 e [5,1]. Comparando 2
com o máximo de [5,1], que é 5, escolhemos
5.
Uma maneira ainda mais clara de escrever essa função é usar
max. Se você se lembra, max é uma função que
pega dois números e retorna o maior deles. Veja como poderíamos
reescrever maximum' usando max:
maximum' :: (Ord a) => [a] -> a
maximum' [] = error "maximum of empty list"
maximum' [x] = x
maximum' (x:xs) = max x (maximum' xs)Que tal isso para elegante! Em essência, o máximo de uma lista é o máximo do primeiro elemento e o máximo da cauda.
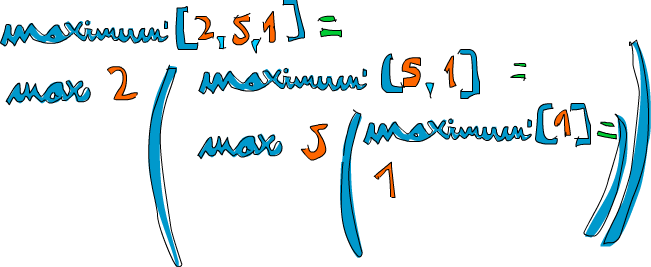
Mais algumas funções recursivas
Agora que sabemos como pensar recursivamente em geral, vamos
implementar algumas funções usando recursão. Primeiro, implementaremos
replicate. replicate recebe um
Int e algum elemento e retorna uma lista que tem várias
repetições do mesmo elemento. Por exemplo, replicate 3 5
retorna [5,5,5]. Vamos pensar na condição de borda. Meu
palpite é que a condição de borda seja 0 ou menos. Se tentarmos replicar
algo zero vezes, ele deve retornar uma lista vazia. Também para números
negativos, porque realmente não faz sentido.
replicate' :: (Num i, Ord i) => i -> a -> [a]
replicate' n x
| n <= 0 = []
| otherwise = x:replicate' (n-1) xUsamos guardas aqui em vez de padrões porque estamos testando uma
condição booleana. Se n for menor ou igual a 0, retorne uma
lista vazia. Caso contrário, retorne uma lista que tenha x
como o primeiro elemento e depois x replicado n-1 vezes
como a cauda. Eventualmente, a parte (n-1) fará com que
nossa função atinja a condição de borda.
Nota: Num não é uma subclasse de
Ord. Isso ocorre porque nem todo tipo de número tem uma
ordenação, por exemplo, números complexos não são ordenados. É por isso
que temos que especificar as restrições de classe Num e
Ord ao fazer adição ou subtração e também comparação.
A seguir, implementaremos take. Ele retira um certo
número de elementos de uma lista. Por exemplo,
take 3 [5,4,3,2,1] retornará [5,4,3]. Se
tentarmos tirar 0 ou menos elementos de uma lista, obtemos uma lista
vazia. Além disso, se tentarmos tirar qualquer coisa de uma lista vazia,
obtemos uma lista vazia. Observe que essas são duas condições de borda
bem ali. Então vamos escrever isso:
take' :: (Num i, Ord i) => i -> [a] -> [a]
take' n _
| n <= 0 = []
take' _ [] = []
take' n (x:xs) = x : take' (n-1) xs
O primeiro padrão especifica que, se tentarmos obter um número 0 ou
negativo de elementos, obteremos uma lista vazia. Observe que estamos
usando _ para corresponder à lista porque não nos
importamos com o que é neste caso. Observe também que usamos uma guarda,
mas sem uma parte otherwise. Isso significa que, se
n for maior que 0, a correspondência cairá para o próximo
padrão. O segundo padrão indica que, se tentarmos tirar qualquer coisa
de uma lista vazia, obteremos uma lista vazia. O terceiro padrão quebra
a lista em uma cabeça e uma cauda. E então afirmamos que pegar
n elementos de uma lista é igual a uma lista que tem
x como cabeça e depois uma lista que pega n-1
elementos da cauda como cauda. Tente usar um pedaço de papel para
escrever como seria a avaliação se tentássemos tirar, digamos, 3 de
[4,3,2,1].
reverse simplesmente inverte uma lista. Pense na
condição de borda. O que é? Vamos lá… é a lista vazia! Uma lista vazia
invertida é igual à própria lista vazia. Ok. E o resto? Bem, você
poderia dizer que, se dividirmos uma lista em uma cabeça e uma cauda, a
lista invertida é igual à cauda invertida e depois a cabeça no
final.
reverse' :: [a] -> [a]
reverse' [] = []
reverse' (x:xs) = reverse' xs ++ [x]Aí está!
Como o Haskell suporta listas infinitas, nossa recursão realmente não
precisa ter uma condição de borda. Mas se não tiver, continuará
produzindo algo infinitamente ou produzirá uma estrutura de dados
infinita, como uma lista infinita. A coisa boa sobre listas infinitas,
porém, é que podemos cortá-las onde quisermos. repeat pega
um elemento e retorna uma lista infinita que apenas tem esse elemento.
Uma implementação recursiva disso é muito fácil, observe.
repeat' :: a -> [a]
repeat' x = x:repeat' xChamar repeat 3 nos dará uma lista que começa com
3 e depois tem uma quantidade infinita de 3s como cauda.
Portanto, chamar repeat 3 seria avaliado como
3:repeat 3, que é 3:(3:repeat 3), que é
3:(3:(3:repeat 3)), etc. repeat 3 nunca
terminará de avaliar, enquanto take 5 (repeat 3) nos dará
uma lista de cinco 3s. Então, essencialmente, é como fazer
replicate 5 3.
zip pega duas listas e as compacta.
zip [1,2,3] [2,3] retorna [(1,2),(2,3)],
porque trunca a lista mais longa para corresponder ao comprimento da
mais curta. E se compactarmos algo com uma lista vazia? Bem, obtemos uma
lista vazia de volta. Então, aí está nossa condição de borda. No
entanto, zip recebe duas listas como parâmetros, então
existem, na verdade, duas condições de borda.
zip' :: [a] -> [b] -> [(a,b)]
zip' _ [] = []
zip' [] _ = []
zip' (x:xs) (y:ys) = (x,y):zip' xs ysOs dois primeiros padrões dizem que, se a primeira lista ou a segunda
lista estiver vazia, obteremos uma lista vazia. O terceiro diz que duas
listas compactadas são iguais a emparelhar suas cabeças e depois
adicionar as caudas compactadas. Compactar [1,2,3] e
['a','b'] acabará tentando compactar [3] com
[]. Os padrões de condição de borda entram em ação e o
resultado é (1,'a'):(2,'b'):[], que é exatamente o mesmo
que [(1,'a'),(2,'b')].
Vamos implementar mais uma função da biblioteca padrão —
elem. Ela pega um elemento e uma lista e verifica se esse
elemento está na lista. A condição de borda, como na maioria das vezes
com listas, é a lista vazia. Sabemos que uma lista vazia não contém
elementos, então certamente não tem os droides que estamos
procurando.
elem' :: (Eq a) => a -> [a] -> Bool
elem' a [] = False
elem' a (x:xs)
| a == x = True
| otherwise = a `elem'` xsBastante simples e esperado. Se a cabeça não for o elemento,
verificamos a cauda. Se chegarmos a uma lista vazia, o resultado é
False.
Rápido, ordene! (Quick, sort!)
Temos uma lista de itens que podem ser ordenados. O tipo deles é uma
instância da typeclass Ord. E agora, queremos ordená-los!
Existe um algoritmo muito legal para ordenação chamado quicksort. É uma
maneira muito inteligente de ordenar itens. Embora leve mais de 10
linhas para implementar o quicksort em linguagens imperativas, a
implementação é muito mais curta e elegante em Haskell. O Quicksort se
tornou uma espécie de “garoto-propaganda” do Haskell. Portanto, vamos
implementá-lo aqui, embora implementar o quicksort em Haskell seja
considerado muito clichê, porque todo mundo faz isso para mostrar como o
Haskell é elegante.

Então, a assinatura de tipo será
quicksort :: (Ord a) => [a] -> [a]. Sem surpresas aí.
A condição de borda? Lista vazia, como é esperado. Uma lista vazia
ordenada é uma lista vazia. Agora vem o algoritmo principal: uma
lista ordenada é uma lista que tem todos os valores menores (ou iguais)
à cabeça da lista na frente (e esses valores são ordenados), depois vem
a cabeça da lista no meio e depois vêm todos os valores maiores que a
cabeça (eles também são ordenados). Observe que dissemos
ordenados duas vezes nesta definição, então provavelmente
teremos que fazer a chamada recursiva duas vezes! Observe também que
definimos usando o verbo é para definir o algoritmo em vez de
dizer faça isso, faça aquilo, depois faça aquilo…. Essa é a
beleza da programação funcional! Como vamos filtrar a lista para obter
apenas os elementos menores que a cabeça da nossa lista e apenas
elementos maiores? Compreensões de lista. Então, vamos mergulhar e
definir esta função.
quicksort :: (Ord a) => [a] -> [a]
quicksort [] = []
quicksort (x:xs) =
let smallerSorted = quicksort [a | a <- xs, a <= x]
biggerSorted = quicksort [a | a <- xs, a > x]
in smallerSorted ++ [x] ++ biggerSortedVamos fazer um pequeno teste para ver se parece se comportar corretamente.
ghci> quicksort [10,2,5,3,1,6,7,4,2,3,4,8,9]
[1,2,2,3,3,4,4,5,6,7,8,9,10]
ghci> quicksort "the quick brown fox jumps over the lazy dog"
" abcdeeefghhijklmnoooopqrrsttuuvwxyz"Booyah! É disso que estou falando! Então, se tivermos, digamos
[5,1,9,4,6,7,3] e quisermos ordená-lo, esse algoritmo
pegará primeiro a cabeça, que é 5, e depois a colocará no
meio de duas listas menores e maiores que ela. Então, em um ponto, você
terá [1,4,3] ++ [5] ++ [9,6,7]. Sabemos que, uma vez que a
lista esteja completamente ordenada, o número 5 permanecerá
no quarto lugar, pois há 3 números menores que ele e 3 números maiores
que ele. Agora, se ordenarmos [1,4,3] e
[9,6,7], temos uma lista ordenada! Ordenamos as duas listas
usando a mesma função. Eventualmente, vamos quebrá-la tanto que
chegaremos a listas vazias e uma lista vazia já está ordenada de certa
forma, em virtude de estar vazia. Aqui está uma ilustração:
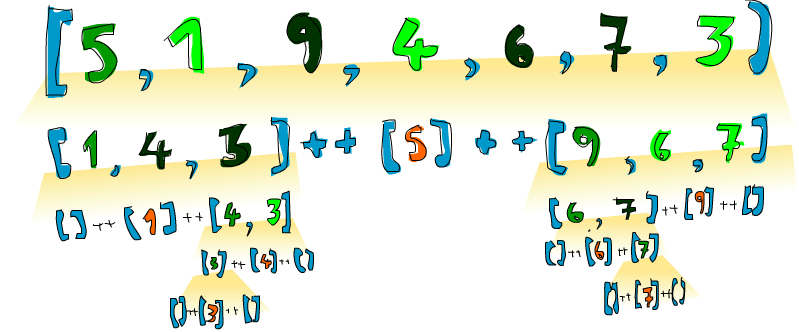
Um elemento que está no lugar e não se moverá mais é representado em laranja. Se você lê-los da esquerda para a direita, verá a lista ordenada. Embora tenhamos escolhido comparar todos os elementos com as cabeças, poderíamos ter usado qualquer elemento para comparar. No quicksort, um elemento com o qual você compara é chamado de pivô. Eles estão em verde aqui. Escolhemos a cabeça porque é fácil de obter por pattern matching. Os elementos menores que o pivô são verde claro e os elementos maiores que o pivô são verde escuro. A coisa de gradiente amarelado representa uma aplicação de quicksort.
Pensando recursivamente
Fizemos um pouco de recursão até agora e, como você provavelmente notou, há um padrão aqui. Normalmente, você define um caso de borda e define uma função que faz algo entre algum elemento e a função aplicada ao resto. Não importa se é uma lista, uma árvore ou qualquer outra estrutura de dados. Uma soma é o primeiro elemento de uma lista mais a soma do restante da lista. Um produto de uma lista é o primeiro elemento da lista vezes o produto do restante da lista. O comprimento de uma lista é um mais o comprimento da cauda da lista. Et cetera, et cetera…

Claro, estes também têm casos de borda. Geralmente, o caso de borda é algum cenário em que uma aplicação recursiva não faz sentido. Ao lidar com listas, o caso de borda é na maioria das vezes a lista vazia. Se você estiver lidando com árvores, o caso de borda geralmente é um nó que não tem filhos.
É semelhante quando você está lidando com números recursivamente. Geralmente tem a ver com algum número e a função aplicada a esse número modificado. Fizemos a função fatorial anteriormente e é o produto de um número e o fatorial desse número menos um. Tal aplicação recursiva não faz sentido com zero, porque os fatoriais são definidos apenas para números inteiros positivos. Muitas vezes, o valor do caso de borda acaba sendo uma identidade. A identidade para multiplicação é 1 porque se você multiplicar algo por 1, você recebe isso de volta. Também ao fazer somas de listas, definimos a soma de uma lista vazia como 0 e 0 é a identidade para adição. No quicksort, o caso de borda é a lista vazia e a identidade também é a lista vazia, porque se você adicionar uma lista vazia a uma lista, apenas obterá a lista original de volta.
Portanto, ao tentar pensar em uma maneira recursiva de resolver um problema, tente pensar em quando uma solução recursiva não se aplica e veja se você pode usar isso como um caso de borda, pense em identidades e pense se você quebrará os parâmetros da função (por exemplo, listas geralmente são quebradas em cabeça e cauda via pattern matching) e em qual parte você usará a chamada recursiva.