Funções de Alta Ordem (Higher Order Functions)

As funções Haskell podem receber funções como parâmetros e retornar funções como valores de retorno. Uma função que faz qualquer uma dessas coisas é chamada de função de alta ordem. Funções de alta ordem não são apenas uma parte da experiência Haskell, elas praticamente são a experiência Haskell. Acontece que, se você deseja definir cálculos definindo o que as coisas são em vez de definir etapas que alteram algum estado e talvez fazendo um loop, as funções de alta ordem são indispensáveis. Elas são uma maneira realmente poderosa de resolver problemas e pensar sobre programas.
Funções curried (Curried functions)
Cada função em Haskell oficialmente aceita apenas um parâmetro. Então
como é possível que definimos e usamos várias funções que aceitam mais
de um parâmetro até agora? Bem, é um truque inteligente! Todas as
funções que aceitavam vários parâmetros até agora eram
funções curried. O que isso significa? Você entenderá
melhor em um exemplo. Vamos pegar nossa boa amiga, a função
max. Parece que ela aceita dois parâmetros e retorna o
maior. Fazer max 4 5 primeiro cria uma função que aceita um
parâmetro e retorna 4 ou esse parâmetro, dependendo de qual
é maior. Então, 5 é aplicado a essa função e essa função
produz nosso resultado desejado. Isso soa complicado, mas na verdade é
um conceito muito legal. As duas chamadas a seguir são equivalentes:
ghci> max 4 5
5
ghci> (max 4) 5
5
Colocar um espaço entre duas coisas é simplesmente aplicação
de função. O espaço é como um operador e tem a maior
precedência. Vamos examinar o tipo de max. É
max :: (Ord a) => a -> a -> a. Isso também pode
ser escrito como max :: (Ord a) => a -> (a -> a).
Isso poderia ser lido como: max pega um a e
retorna (essa é a ->) uma função que pega um
a e retorna um a. É por isso que o tipo de
retorno e os parâmetros das funções são simplesmente separados por
setas.
Então, como isso nos beneficia? Simplesmente falando, se chamarmos uma função com poucos parâmetros, recebemos de volta uma função parcialmente aplicada, o que significa uma função que aceita tantos parâmetros quanto deixamos de fora. Usar a aplicação parcial (chamar funções com poucos parâmetros, se você preferir) é uma maneira interessante de criar funções em tempo real para que possamos passá-las para outra função ou preenchê-las com alguns dados.
Dê uma olhada nesta função ofensivamente simples:
multThree :: (Num a) => a -> a -> a -> a
multThree x y z = x * y * zO que realmente acontece quando fazmos multThree 3 5 9
ou ((multThree 3) 5) 9? Primeiro, 3 é aplicado
a multThree, porque eles são separados por um espaço. Isso
cria uma função que aceita um parâmetro e retorna uma função. Então,
5 é aplicado a isso, o que cria uma função que receberá um
parâmetro e o multiplicará por 15. 9 é aplicado a essa
função e o resultado é 135 ou algo assim. Lembre-se de que o tipo dessa
função também pode ser escrito como
multThree :: (Num a) => a -> (a -> (a -> a)). A
coisa antes da -> é o parâmetro que uma função aceita e
a coisa depois dela é o que ela retorna. Portanto, nossa função pega um
a e retorna uma função do tipo
(Num a) => a -> (a -> a). Da mesma forma, essa
função pega um a e retorna uma função do tipo
(Num a) => a -> a. E essa função, finalmente, apenas
pega um a e retorna um a. Dê uma olhada
nisto:
ghci> let multTwoWithNine = multThree 9
ghci> multTwoWithNine 2 3
54
ghci> let multWithEighteen = multTwoWithNine 2
ghci> multWithEighteen 10
180Ao chamar funções com poucos parâmetros, por assim dizer, estamos
criando novas funções em tempo real. E se quiséssemos criar uma função
que pega um número e o compara com 100? Poderíamos fazer
algo assim:
compareWithHundred :: (Num a, Ord a) => a -> Ordering
compareWithHundred x = compare 100 xSe o chamarmos com 99, ele retornará um GT.
Coisa simples. Observe que o x está no lado direito de
ambos os lados da equação. Agora vamos pensar sobre o que
compare 100 retorna. Ele retorna uma função que pega um
número e o compara com 100. Uau! Não é essa a função que
queríamos? Podemos reescrever isso como:
compareWithHundred :: (Num a, Ord a) => a -> Ordering
compareWithHundred = compare 100A declaração de tipo permanece a mesma, porque
compare 100 retorna uma função. Compare tem um tipo de
(Ord a) => a -> (a -> Ordering) e chamá-lo com
100 retorna um
(Num a, Ord a) => a -> Ordering. A restrição de
classe adicional aparece lá porque 100 também faz parte da
typeclass Num.
Yo! Certifique-se de entender realmente como as funções curried e a aplicação parcial funcionam, porque elas são realmente importantes!
Funções infix também podem ser parcialmente aplicadas usando seções. Para seccionar uma função infix, simplesmente cerque-a com parênteses e forneça apenas um parâmetro de um lado. Isso cria uma função que aceita um parâmetro e o aplica ao lado que está faltando um operando. Uma função insultuosamente trivial:
divideByTen :: (Floating a) => a -> a
divideByTen = (/10)Chamar, digamos, divideByTen 200 é equivalente a fazer
200 / 10, assim como fazer (/10) 200. Uma
função que verifica se um caractere fornecido a ela é uma letra
maiúscula:
isUpperAlphanum :: Char -> Bool
isUpperAlphanum = (`elem` ['A'..'Z'])A única coisa especial sobre as seções é usar -. A
partir da definição de seções, (-4) resultaria em uma
função que pega um número e subtrai 4 dele. No entanto, por
conveniência, (-4) significa menos quatro. Portanto, se
você quiser fazer uma função que subtrai 4 do número que obtém como
parâmetro, aplique parcialmente a função subtract assim:
(subtract 4).
O que acontece se tentarmos apenas fazer multThree 3 4
no GHCI em vez de vinculá-lo a um nome com um let ou passá-lo
para outra função?
ghci> multThree 3 4
<interactive>:1:1: error: [GHC-39999]
• No instance for ‘Show (a0 -> a0)’ arising from a use of ‘print’
(maybe you haven't applied a function to enough arguments?)
• In a stmt of an interactive GHCi command: print itO GHCI está nos dizendo que a expressão produziu uma função do tipo
a -> a, mas não sabe como imprimi-la na tela. Funções
não são instâncias da typeclass Show, então não podemos
obter uma representação de string elegante de uma função. Quando
fazemos, digamos, 1 + 1 no prompt do GHCI, ele primeiro
calcula isso para 2 e depois chama show em
2 para obter uma representação textual desse número. E a
representação textual de 2 é apenas a string
"2", que é então impressa em nossa tela.
Algum alto-ordenismo está em ordem
As funções podem receber funções como parâmetros e também retornar funções. Para ilustrar isso, vamos fazer uma função que pega uma função e a aplica duas vezes a algo!
applyTwice :: (a -> a) -> a -> a
applyTwice f x = f (f x)
Em primeiro lugar, observe a declaração de tipo. Antes, não
precisávamos de parênteses porque -> é naturalmente
associativo à direita. No entanto, aqui, eles são obrigatórios. Eles
indicam que o primeiro parâmetro é uma função que pega algo e retorna a
mesma coisa. O segundo parâmetro é algo desse tipo também e o valor de
retorno também é do mesmo tipo. Poderíamos ler essa declaração de tipo
da maneira curried, mas para nos poupar de dor de cabeça, apenas diremos
que essa função aceita dois parâmetros e retorna uma coisa. O primeiro
parâmetro é uma função (do tipo a -> a) e o segundo é o
mesmo a. A função também pode ser
Int -> Int ou String -> String ou
qualquer outra coisa. Mas então, o segundo parâmetro também deve ser
desse tipo.
Nota: A partir de agora, diremos que as funções
aceitam vários parâmetros, apesar de cada função aceitar apenas um
parâmetro e retornar funções parcialmente aplicadas até chegarmos a uma
função que retorna um valor sólido. Portanto, por uma questão de
simplicidade, diremos que a -> a -> a aceita dois
parâmetros, embora saibamos o que realmente está acontecendo nos
bastidores.
O corpo da função é bastante simples. Apenas usamos o parâmetro
f como uma função, aplicando x a ele
separando-os com um espaço e depois aplicando o resultado a
f novamente. De qualquer forma, brincando com a função:
ghci> applyTwice (+3) 10
16
ghci> applyTwice (++ " HAHA") "HEY"
"HEY HAHA HAHA"
ghci> applyTwice ("HAHA " ++) "HEY"
"HAHA HAHA HEY"
ghci> applyTwice (multThree 2 2) 9
144
ghci> applyTwice (3:) [1]
[3,3,1]A grandiosidade e utilidade da aplicação parcial é evidente. Se nossa função exigir que passemos a ela uma função que aceita apenas um parâmetro, podemos apenas aplicar parcialmente uma função até o ponto em que ela aceita apenas um parâmetro e depois passá-la.
Agora vamos usar programação de alta ordem para implementar uma
função realmente útil que está na biblioteca padrão. É chamada de
zipWith. Ela pega uma função e duas listas como parâmetros
e, em seguida, une as duas listas aplicando a função entre os elementos
correspondentes. Veja como a implementaremos:
zipWith' :: (a -> b -> c) -> [a] -> [b] -> [c]
zipWith' _ [] _ = []
zipWith' _ _ [] = []
zipWith' f (x:xs) (y:ys) = f x y : zipWith' f xs ysOlhe para a declaração de tipo. O primeiro parâmetro é uma função que
pega duas coisas e produz uma terceira coisa. Elas não precisam ser do
mesmo tipo, mas podem ser. O segundo e o terceiro parâmetro são listas.
O resultado também é uma lista. A primeira deve ser uma lista de
as, porque a função de união pega as como seu
primeiro argumento. A segunda deve ser uma lista de bs,
porque o segundo parâmetro da função de união é do tipo b.
O resultado é uma lista de cs. Se a declaração de tipo de
uma função diz que ela aceita uma função a -> b -> c
como parâmetro, ela também aceitará uma função
a -> a -> a, mas não o contrário! Lembre-se de que
quando você está criando funções, especialmente as de alta ordem, e não
tem certeza do tipo, pode simplesmente tentar omitir a declaração de
tipo e verificar o que o Haskell infere que seja usando
:t.
A ação na função é bastante semelhante ao zip normal. As
condições de borda são as mesmas, só que há um argumento extra, a função
de união, mas esse argumento não importa nas condições de borda, então
apenas usamos um _ para ele. E o corpo da função no último
padrão também é semelhante ao zip, só que não faz
(x,y), mas f x y. Uma única função de alta
ordem pode ser usada para uma infinidade de tarefas diferentes se for
geral o suficiente. Aqui está uma pequena demonstração de todas as
coisas diferentes que nossa função zipWith' pode fazer:
ghci> zipWith' (+) [4,2,5,6] [2,6,2,3]
[6,8,7,9]
ghci> zipWith' max [6,3,2,1] [7,3,1,5]
[7,3,2,5]
ghci> zipWith' (++) ["foo ", "bar ", "baz "] ["fighters", "hoppers", "aldrin"]
["foo fighters","bar hoppers","baz aldrin"]
ghci> zipWith' (*) (replicate 5 2) [1..]
[2,4,6,8,10]
ghci> zipWith' (zipWith' (*)) [[1,2,3],[3,5,6],[2,3,4]] [[3,2,2],[3,4,5],[5,4,3]]
[[3,4,6],[9,20,30],[10,12,12]]Como você pode ver, uma única função de alta ordem pode ser usada de maneiras muito versáteis. A programação imperativa geralmente usa coisas como loops for, loops while, definir algo em uma variável, verificar seu estado, etc. para obter algum comportamento e, em seguida, envolvê-lo em uma interface, como uma função. A programação funcional usa funções de alta ordem para abstrair padrões comuns, como examinar duas listas em pares e fazer algo com esses pares ou obter um conjunto de soluções e eliminar as que você não precisa.
Implementaremos outra função que já está na biblioteca padrão,
chamada flip. Flip simplesmente pega uma função e retorna
uma função que é como nossa função original, apenas os dois primeiros
argumentos são invertidos. Podemos implementá-la assim:
flip' :: (a -> b -> c) -> (b -> a -> c)
flip' f = g
where g x y = f y xLendo a declaração de tipo, dizemos que ela pega uma função que pega
um a e um b e retorna uma função que pega um
b e um a. Mas como as funções são curried por
padrão, o segundo par de parênteses é realmente desnecessário, porque
-> é associativo à direita por padrão.
(a -> b -> c) -> (b -> a -> c) é o mesmo que
(a -> b -> c) -> (b -> (a -> c)), que é o
mesmo que (a -> b -> c) -> b -> a -> c.
Escrevemos que g x y = f y x. Se isso for verdade, então
f y x = g x y deve também ser verdade, certo? Tendo isso em
mente, podemos definir essa função de uma maneira ainda mais
simples.
flip' :: (a -> b -> c) -> b -> a -> c
flip' f y x = f x yAqui, aproveitamos o fato de que as funções são curried. Quando
chamamos flip' f sem os parâmetros y e
x, ele retornará um f que pega esses dois
parâmetros, mas os chama invertidos. Mesmo que funções invertidas
geralmente sejam passadas para outras funções, podemos aproveitar o
currying ao criar funções de alta ordem pensando no futuro e escrevendo
qual seria o resultado final se fossem chamadas totalmente
aplicadas.
ghci> flip' zip [1,2,3,4,5] "hello"
[('h',1),('e',2),('l',3),('l',4),('o',5)]
ghci> zipWith (flip' div) [2,2..] [10,8,6,4,2]
[5,4,3,2,1]Maps e filters (Maps and filters)
map pega uma função e uma lista e
aplica essa função a cada elemento da lista, produzindo uma nova lista.
Vamos ver qual é a sua assinatura de tipo e como ela é definida.
map :: (a -> b) -> [a] -> [b]
map _ [] = []
map f (x:xs) = f x : map f xsA assinatura de tipo diz que ele pega uma função que pega um
a e retorna um b, uma lista de as
e retorna uma lista de bs. É interessante que apenas
olhando para a assinatura de tipo de uma função, às vezes você pode
dizer o que ela faz. map é uma daquelas funções de alta
ordem realmente versáteis que podem ser usadas de milhões de maneiras
diferentes. Aqui está em ação:
ghci> map (+3) [1,5,3,1,6]
[4,8,6,4,9]
ghci> map (++ "!") ["BIFF", "BANG", "POW"]
["BIFF!","BANG!","POW!"]
ghci> map (replicate 3) [3..6]
[[3,3,3],[4,4,4],[5,5,5],[6,6,6]]
ghci> map (map (^2)) [[1,2],[3,4,5,6],[7,8]]
[[1,4],[9,16,25,36],[49,64]]
ghci> map fst [(1,2),(3,5),(6,3),(2,6),(2,5)]
[1,3,6,2,2]Você provavelmente notou que cada uma delas poderia ser alcançada com
uma compreensão de lista. map (+3) [1,5,3,1,6] é o mesmo
que escrever [x+3 | x <- [1,5,3,1,6]]. No entanto, usar
map é muito mais legível para casos em que você aplica
apenas alguma função aos elementos de uma lista, especialmente quando
você está lidando com maps de maps e então a coisa toda com muitos
colchetes pode ficar um pouco confusa.
filter é uma função que pega um
predicado (um predicado é uma função que diz se algo é verdadeiro ou
não, então, no nosso caso, uma função que retorna um valor booleano) e
uma lista e retorna a lista de elementos que satisfazem o predicado. A
assinatura de tipo e implementação são assim:
filter :: (a -> Bool) -> [a] -> [a]
filter _ [] = []
filter p (x:xs)
| p x = x : filter p xs
| otherwise = filter p xsCoisa bem simples. Se p x for avaliado como
True, o elemento será incluído na nova lista. Se não, fica
de fora. Alguns exemplos de uso:
ghci> filter (>3) [1,5,3,2,1,6,4,3,2,1]
[5,6,4]
ghci> filter (==3) [1,2,3,4,5]
[3]
ghci> filter even [1..10]
[2,4,6,8,10]
ghci> let notNull x = not (null x) in filter notNull [[1,2,3],[],[3,4,5],[2,2],[],[],[]]
[[1,2,3],[3,4,5],[2,2]]
ghci> filter (`elem` ['a'..'z']) "u LaUgH aT mE BeCaUsE I aM diFfeRent"
"uagameasadifeent"
ghci> filter (`elem` ['A'..'Z']) "i Laugh At you Because u R All The Same"
"LABRATS"Tudo isso também poderia ser alcançado com compreensões de lista pelo
uso de predicados. Não há regra definida para quando usar
map e filter versus usar compreensão de lista,
você apenas tem que decidir o que é mais legível, dependendo do código e
do contexto. O equivalente filter da aplicação de vários
predicados em uma compreensão de lista é filtrar algo várias vezes ou
unir os predicados com a função lógica &&.
Lembra da nossa função quicksort do capítulo
anterior? Usamos compreensões de lista para filtrar os elementos da
lista que são menores (ou iguais) e maiores que o pivô. Podemos alcançar
a mesma funcionalidade de uma maneira mais legível usando
filter:
quicksort :: (Ord a) => [a] -> [a]
quicksort [] = []
quicksort (x:xs) =
let smallerSorted = quicksort (filter (<=x) xs)
biggerSorted = quicksort (filter (>x) xs)
in smallerSorted ++ [x] ++ biggerSorted
Mapear e filtrar é o pão com manteiga da caixa de ferramentas de todo
programador funcional. Uh. Não importa se você faz isso com as funções
map e filter ou compreensões de lista.
Lembre-se de como resolvemos o problema de encontrar triângulos
retângulos com uma certa circunferência. Com a programação imperativa,
teríamos resolvido aninhando três loops e testando se a combinação atual
satisfaz um triângulo retângulo e se tem o perímetro certo. Se for esse
o caso, teríamos imprimido na tela ou algo assim. Na programação
funcional, esse padrão é alcançado com mapeamento e filtragem. Você faz
uma função que pega um valor e produz algum resultado. Mapeamos essa
função sobre uma lista de valores e, em seguida, filtramos a lista
resultante para os resultados que satisfazem nossa pesquisa. Graças à
preguiça de Haskell, mesmo se você mapear algo sobre uma lista várias
vezes e filtrá-la várias vezes, ele passará apenas pela lista uma
vez.
Vamos encontrar o maior número abaixo de 100.000 divisível por 3829. Para fazer isso, vamos filtrar um conjunto de possibilidades nas quais sabemos que a solução está.
largestDivisible :: (Integral a) => a
largestDivisible = head (filter p [100000,99999..])
where p x = x `mod` 3829 == 0Primeiro fazemos uma lista de todos os números menores que 100.000, descendente. Em seguida, filtramos pelo nosso predicado e, como os números são classificados de maneira descendente, o maior número que satisfaz nosso predicado é o primeiro elemento da lista filtrada. Nós nem precisávamos usar uma lista finita para o nosso conjunto inicial. Essa é a preguiça em ação novamente. Como acabamos usando apenas a cabeça da lista filtrada, não importa se a lista filtrada é finita ou infinita. A avaliação para quando a primeira solução adequada é encontrada.
A seguir, vamos encontrar a soma de todos os quadrados
ímpares que são menores que 10.000. Mas primeiro, como vamos
usá-la em nossa solução, vamos introduzir a função takeWhile. Ela pega um predicado e uma
lista e depois vai desde o início da lista e retorna seus elementos
enquanto o predicado for verdadeiro. Uma vez que um elemento é
encontrado para o qual o predicado não se sustenta, ele para. Se
quiséssemos obter a primeira palavra da string
"elephants know how to party", poderíamos fazer
takeWhile (/=' ') "elephants know how to party" e
retornaria "elephants". Ok. A soma de todos os quadrados
ímpares que são menores que 10.000. Primeiro, começaremos mapeando a
função (^2) para a lista infinita [1..]. Em
seguida, filtramos para obter apenas os ímpares. E então, vamos tirar
elementos dessa lista enquanto forem menores que 10.000. Finalmente,
obteremos a soma dessa lista. Nós nem precisamos definir uma função para
isso, podemos fazê-lo em uma linha no GHCI:
ghci> sum (takeWhile (<10000) (filter odd (map (^2) [1..])))
166650Incrível! Começamos com alguns dados iniciais (a lista infinita de todos os números naturais) e depois mapeamos sobre ela, filtramos e cortamos até que atenda às nossas necessidades e depois apenas somamos. Também poderíamos ter escrito isso usando compreensões de lista:
ghci> sum (takeWhile (<10000) [n^2 | n <- [1..], odd (n^2)])
166650É uma questão de gosto qual você acha mais bonita. Mais uma vez, a
propriedade de preguiça de Haskell é o que torna isso possível. Podemos
mapear e filtrar uma lista infinita, porque ela não mapeará e filtrará
imediatamente, atrasará essas ações. Somente quando forçamos o Haskell a
nos mostrar a soma, a função sum diz ao
takeWhile que precisa desses números.
takeWhile força a filtragem e o mapeamento a ocorrer, mas
apenas até que um número maior ou igual a 10.000 seja encontrado.
Para o nosso próximo problema, lidaremos com as sequências de Collatz. Pegamos um número natural. Se esse número for par, nós o dividimos por dois. Se for ímpar, multiplicamos por 3 e depois adicionamos 1 a isso. Pegamos o número resultante e aplicamos a mesma coisa a ele, o que produz um novo número e assim por diante. Em essência, obtemos uma cadeia de números. Pensa-se que, para todos os números iniciais, as cadeias terminam no número 1. Portanto, se pegarmos o número inicial 13, obteremos esta sequência: 13, 40, 20, 10, 5, 16, 8, 4, 2, 1. 13*3 + 1 é igual a 40. 40 dividido por 2 é 20, etc. Vemos que a cadeia tem 10 termos.
Agora, o que queremos saber é o seguinte: para todos os números iniciais entre 1 e 100, quantas cadeias têm um comprimento superior a 15? Primeiro, escreveremos uma função que produz uma cadeia:
chain :: (Integral a) => a -> [a]
chain 1 = [1]
chain n
| even n = n:chain (n `div` 2)
| odd n = n:chain (n*3 + 1)Como as cadeias terminam em 1, esse é o caso de borda. Esta é uma função recursiva bastante padrão.
ghci> chain 10
[10,5,16,8,4,2,1]
ghci> chain 1
[1]
ghci> chain 30
[30,15,46,23,70,35,106,53,160,80,40,20,10,5,16,8,4,2,1]Yay! Parece estar funcionando corretamente. E agora, a função que nos diz a resposta para nossa pergunta:
numLongChains :: Int
numLongChains = length (filter isLong (map chain [1..100]))
where isLong xs = length xs > 15Mapeamos a função chain para [1..100] para
obter uma lista de cadeias, que são representadas como listas. Em
seguida, filtramos por um predicado que apenas verifica se o comprimento
de uma lista é maior que 15. Depois de fazermos a filtragem, vemos
quantas cadeias restam na lista resultante.
Nota: Esta função tem um tipo de
numLongChains :: Int porque length retorna um
Int em vez de um Num a por razões históricas.
Se quiséssemos retornar um Num a mais geral, poderíamos ter
usado fromIntegral no comprimento resultante.
Usando map, também podemos fazer coisas como
map (*) [0..], se não por qualquer outro motivo a não ser
ilustrar como o currying funciona e como as funções (parcialmente
aplicadas) são valores reais que você pode passar para outras funções ou
colocar em listas (você apenas não pode transformá-las em strings). Até
agora, mapeamos apenas funções que aceitam um parâmetro sobre listas,
como map (*2) [0..] para obter uma lista do tipo
(Num a) => [a], mas também podemos fazer
map (*) [0..] sem problemas. O que acontece aqui é que o
número na lista é aplicado à função *, que tem um tipo de
(Num a) => a -> a -> a. A aplicação de apenas um
parâmetro a uma função que aceita dois parâmetros retorna uma função que
aceita um parâmetro. Se mapearmos * sobre a lista
[0..], receberemos uma lista de funções que aceitam apenas
um parâmetro, então (Num a) => [a -> a].
map (*) [0..] produz uma lista como a que obteríamos
escrevendo [(0*),(1*),(2*),(3*),(4*),(5*)...
ghci> let listOfFuncs = map (*) [0..]
ghci> (listOfFuncs !! 4) 5
20Obter o elemento com o índice 4 da nossa lista retorna
uma função equivalente a (4*). E então, apenas aplicamos
5 a essa função. Então é como escrever (4*) 5
ou apenas 4 * 5.
Lambdas

Lambdas são basicamente funções anônimas que são usadas porque
precisamos de algumas funções apenas uma vez. Normalmente, fazemos um
lambda com o único objetivo de passá-lo para uma função de alta ordem.
Para fazer um lambda, escrevemos uma \ (porque meio que se
parece com a letra grega lambda se você apertar os olhos com força o
suficiente) e depois escrevemos os parâmetros, separados por espaços.
Depois disso vem uma -> e depois o corpo da função.
Geralmente os cercamos por parênteses, porque, caso contrário, eles se
estendem até a direita.
Se você olhar cerca de 5 polegadas para cima, verá que usamos uma
ligação where em nossa função numLongChains para
criar a função isLong com o único objetivo de passá-la para
o filter. Bem, em vez de fazer isso, podemos usar um
lambda:
numLongChains :: Int
numLongChains = length (filter (\xs -> length xs > 15) (map chain [1..100]))Lambdas são expressões, é por isso que podemos apenas passá-las
assim. A expressão (\xs -> length xs > 15) retorna
uma função que nos diz se o comprimento da lista passada para ela é
maior que 15.

Pessoas que não estão bem familiarizadas com o funcionamento do
currying e da aplicação parcial costumam usar lambdas onde não precisam.
Por exemplo, as expressões map (+3) [1,6,3,2] e
map (\x -> x + 3) [1,6,3,2] são equivalentes, pois tanto
(+3) quanto (\x -> x + 3) são funções que
pegam um número e adicionam 3 a ele. Escusado será dizer que fazer um
lambda, neste caso, é estúpido, pois o uso de aplicativos parciais é
muito mais legível.
Como as funções normais, os lambdas podem receber qualquer número de parâmetros:
ghci> zipWith (\a b -> (a * 30 + 3) / b) [5,4,3,2,1] [1,2,3,4,5]
[153.0,61.5,31.0,15.75,6.6]E, como funções normais, você pode fazer pattern match em lambdas. A
única diferença é que você não pode definir vários padrões para um
parâmetro, como criar um padrão [] e um (x:xs)
para o mesmo parâmetro e depois fazer com que os valores caiam. Se um
pattern matching falhar em um lambda, ocorrerá um erro de tempo de
execução, portanto, tenha cuidado ao fazer pattern matching em
lambdas!
ghci> map (\(a,b) -> a + b) [(1,2),(3,5),(6,3),(2,6),(2,5)]
[3,8,9,8,7]Os lambdas são normalmente cercados por parênteses, a menos que queiramos que eles se estendam até a direita. Aqui está algo interessante: devido à maneira como as funções são curried por padrão, essas duas são equivalentes:
addThree :: (Num a) => a -> a -> a -> a
addThree x y z = x + y + zaddThree :: (Num a) => a -> a -> a -> a
addThree = \x -> \y -> \z -> x + y + zSe definirmos uma função como essa, é óbvio por que a declaração de
tipo é o que é. Existem três -> na declaração de tipo e
na equação. Mas, é claro, a primeira maneira de escrever funções é muito
mais legível, a segunda é praticamente um truque para ilustrar o
currying.
No entanto, há momentos em que o uso dessa notação é legal. Acho que
a função flip é a mais legível quando definida assim:
flip' :: (a -> b -> c) -> b -> a -> c
flip' f = \x y -> f y xEmbora seja o mesmo que escrever flip' f x y = f y x,
tornamos óbvio que isso será usado para produzir uma nova função na
maioria das vezes. O caso de uso mais comum com flip é
chamá-lo apenas com o parâmetro da função e depois passar a função
resultante para um map ou um filter. Portanto, use lambdas dessa maneira
quando quiser tornar explícito que sua função se destina principalmente
a ser parcialmente aplicada e repassada a uma função como parâmetro.
Apenas dobras e cavalos (Only folds and horses)

Quando estávamos lidando com a recursão, notamos um tema em muitas
das funções recursivas que operavam nas listas. Normalmente, teríamos um
caso de borda para a lista vazia. Introduziríamos o padrão
x:xs e depois faríamos alguma ação que envolve um único
elemento e o restante da lista. Acontece que esse é um padrão muito
comum; portanto, algumas funções muito úteis foram introduzidas para
encapsulá-lo. Essas funções são chamadas de dobras (folds). Elas são
como a função map, apenas reduzem a lista a um único
valor.
Uma dobra pega uma função binária, um valor inicial (gosto de chamá-lo de acumulador) e uma lista para dobrar. A própria função binária leva dois parâmetros. A função binária é chamada com o acumulador e o primeiro (ou último) elemento e produz um novo acumulador. Em seguida, a função binária é chamada novamente com o novo acumulador e o agora novo primeiro (ou último) elemento, e assim por diante. Depois de percorrer toda a lista, apenas o acumulador permanece, que é o que reduzimos a lista.
Primeiro, vamos dar uma olhada na função foldl, também chamada de dobra esquerda
(left fold). Ele dobra a lista do lado esquerdo. A função binária é
aplicada entre o valor inicial e a cabeça da lista. Isso produz um novo
valor acumulador e a função binária é chamada com esse valor e o próximo
elemento, etc.
Vamos implementar sum novamente, apenas desta vez,
usaremos uma dobra em vez de recursão explícita.
sum' :: (Num a) => [a] -> a
sum' xs = foldl (\acc x -> acc + x) 0 xsTestando, um dois três:
ghci> sum' [3,5,2,1]
11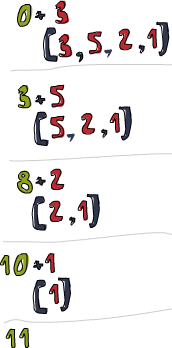
Vamos dar uma olhada em profundidade como essa dobra acontece.
\acc x -> acc + x é a função binária. 0 é o
valor inicial e xs é a lista a ser dobrada. Agora,
primeiro, 0 é usado como o parâmetro acc para
a função binária e 3 é usado como o parâmetro
x (ou o elemento atual). 0 + 3 produz um
3 e se torna o novo valor do acumulador, por assim dizer.
Em seguida, 3 é usado como o valor do acumulador e
5 como o elemento atual e 8 se torna o novo
valor do acumulador. Avançando, 8 é o valor do acumulador,
2 é o elemento atual, o novo valor do acumulador é
10. Finalmente, esse 10 é usado como valor do
acumulador e 1 como o elemento atual, produzindo um
11. Parabéns, você fez uma dobra!
Este diagrama profissional à esquerda ilustra como uma dobra acontece, passo a passo (dia a dia!). O número marrom esverdeado é o valor do acumulador. Você pode ver como a lista é meio consumida do lado esquerdo pelo acumulador. Om nom nom nom! Se levarmos em conta que as funções são curried, podemos escrever essa implementação cada vez mais sucintamente, assim:
sum' :: (Num a) => [a] -> a
sum' = foldl (+) 0A função lambda (\acc x -> acc + x) é a mesma que
(+). Podemos omitir o xs como parâmetro porque
chamar foldl (+) 0 retornará uma função que recebe uma
lista. De um modo geral, se você tiver uma função como
foo a = bar b a, poderá reescrevê-la como
foo = bar b, por causa do currying.
De qualquer forma, vamos implementar outra função com uma dobra
esquerda antes de passar para as dobras direitas. Tenho certeza que
todos vocês sabem que elem verifica se um valor faz parte
de uma lista, então não vou entrar nisso novamente (ops, acabei de
fazer!). Vamos implementá-lo com uma dobra esquerda.
elem' :: (Eq a) => a -> [a] -> Bool
elem' y ys = foldl (\acc x -> if x == y then True else acc) False ysBem, bem, bem, o que temos aqui? O valor inicial e o acumulador aqui
é um valor booleano. O tipo do valor acumulador e o resultado final são
sempre os mesmos ao lidar com dobras. Lembre-se de que, se você não
souber o que usar como valor inicial, isso lhe dará uma ideia. Começamos
com False. Faz sentido usar False como valor
inicial. Assumimos que não está lá. Além disso, se chamarmos uma dobra
em uma lista vazia, o resultado será apenas o valor inicial. Em seguida,
verificamos se o elemento atual é o elemento que estamos procurando. Se
for, definimos o acumulador como True. Se não for, apenas
deixamos o acumulador inalterado. Se era False antes,
permanece assim, porque esse elemento atual não é ele. Se era
True, deixamos assim.
A dobra direita, foldr funciona
de maneira semelhante à dobra esquerda, apenas o acumulador consome os
valores da direita. Além disso, a função binária da dobra esquerda tem o
acumulador como o primeiro parâmetro e o valor atual como o segundo
(então \acc x -> ...), a função binária da dobra direita
tem o valor atual como o primeiro parâmetro e o acumulador como o
segundo (então \x acc -> ...). Meio que faz sentido que
a dobra direita tenha o acumulador à direita, porque dobra do lado
direito.
O valor do acumulador (e, portanto, o resultado) de uma dobra pode ser de qualquer tipo. Pode ser um número, um booleano ou até uma nova lista. Implementaremos a função map com uma dobra direita. O acumulador será uma lista, acumularemos a lista mapeada elemento por elemento. A partir disso, é óbvio que o elemento inicial será uma lista vazia.
map' :: (a -> b) -> [a] -> [b]
map' f xs = foldr (\x acc -> f x : acc) [] xsSe estamos mapeando (+3) a [1,2,3],
abordamos a lista do lado direito. Pegamos o último elemento, que é
3 e aplicamos a função a ele, que acaba sendo
6. Em seguida, o anexamos ao acumulador, que é
[]. 6:[] é [6] e agora é o
acumulador. Nós aplicamos (+3) a 2, isso é
5 e nós o anexamos (:) ao acumulador, então o
acumulador agora é [5,6]. Nós aplicamos (+3) a
1 e anexamos isso ao acumulador e, portanto, o valor final
é [4,5,6].
Obviamente, poderíamos ter implementado essa função com uma dobra
esquerda também. Seria
map' f xs = foldl (\acc x -> acc ++ [f x]) [] xs, mas o
problema é que a função ++ é muito mais cara que
:, então costumamos usar dobras direitas quando estamos
construindo novas listas a partir de uma lista.
Se você inverter uma lista, poderá fazer uma dobra direita nela,
exatamente como teria feito uma dobra esquerda e vice-versa. Às vezes
você nem precisa fazer isso. A função sum pode ser
implementada praticamente na mesma com uma dobra esquerda e direita. Uma
grande diferença é que as dobras direitas funcionam em listas infinitas,
enquanto as esquerdas não! Para dizer claramente, se você pegar uma
lista infinita em algum momento e a dobrar da direita, acabará chegando
ao início da lista. No entanto, se você pegar uma lista infinita em um
ponto e tentar dobrá-la da esquerda, nunca chegará ao fim!
As dobras podem ser usadas para implementar qualquer função em que você percorra uma lista uma vez, elemento por elemento, e depois retorne algo com base nisso. Sempre que você quiser percorrer uma lista para retornar algo, é provável que você queira uma dobra. É por isso que as dobras são, juntamente com maps e filters, um dos tipos mais úteis de funções na programação funcional.
As funções foldl1 e foldr1 funcionam muito como
foldl e foldr, somente você não precisa
fornecer a elas um valor inicial explícito. Eles assumem o primeiro (ou
último) elemento da lista como o valor inicial e iniciam a dobra com o
elemento próximo a ele. Com isso em mente, a função sum
pode ser implementada assim: sum = foldl1 (+). Como
dependem das listas que dobram, com pelo menos um elemento, causam erros
de tempo de execução se chamados com listas vazias. foldl e
foldr, por outro lado, funcionam bem com listas vazias. Ao
fazer uma dobra, pense em como ela age em uma lista vazia. Se a função
não fizer sentido quando receber uma lista vazia, você provavelmente
poderá usar um foldl1 ou foldr1 para
implementá-la.
Apenas para mostrar como as dobras são poderosas, implementaremos um monte de funções da biblioteca padrão usando dobras:
maximum' :: (Ord a) => [a] -> a
maximum' = foldr1 (\x acc -> if x > acc then x else acc)
reverse' :: [a] -> [a]
reverse' = foldl (\acc x -> x : acc) []
product' :: (Num a) => [a] -> a
product' = foldr1 (*)
filter' :: (a -> Bool) -> [a] -> [a]
filter' p = foldr (\x acc -> if p x then x : acc else acc) []
head' :: [a] -> a
head' = foldr1 (\x _ -> x)
last' :: [a] -> a
last' = foldl1 (\_ x -> x)head é melhor implementado por pattern matching, mas
isso apenas mostra, você ainda pode alcançá-lo usando dobras. Nossa
definição reverse' é bastante inteligente, eu acho. Pegamos
um valor inicial de uma lista vazia e depois abordamos nossa lista da
esquerda e apenas anexamos ao nosso acumulador. No final, construímos
uma lista invertida.
\acc x -> x : acc meio que se parece com a função
:, apenas os parâmetros são invertidos. É por isso que
também poderíamos ter escrito nosso reverso como
foldl (flip (:)) [].
Outra maneira de imaginar dobras direita e esquerdas é assim: digamos
que temos uma dobra direita e a função binária é f e o
valor inicial é z. Se estamos dobrando a direita sobre a
lista [3,4,5,6], estamos essencialmente fazendo isso:
f 3 (f 4 (f 5 (f 6 z))). f é chamado com o
último elemento na lista e o acumulador, esse valor é dado como o
acumulador para o penúltimo valor e assim por diante. Se tomarmos
f como + e o valor inicial do acumulador for
0, isso é 3 + (4 + (5 + (6 + 0))). Ou se
escrevermos + como uma função de prefixo, isso é
(+) 3 ((+) 4 ((+) 5 ((+) 6 0))). Da mesma forma, fazer uma
dobra esquerda sobre essa lista com g como função binária e
z como o acumulador é o equivalente a
g (g (g (g z 3) 4) 5) 6. Se usarmos flip (:)
como a função binária e [] como acumulador (portanto,
estamos revertendo a lista), então esse é o equivalente a
flip (:) (flip (:) (flip (:) (flip (:) [] 3) 4) 5) 6. E com
certeza, se você avaliar essa expressão, receberá
[6,5,4,3].
scanl e scanr são como foldl e
foldr, apenas relatam todos os estados intermediários do
acumulador na forma de uma lista. Existem também scanl1 e
scanr1, que são análogos a foldl1 e
foldr1.
ghci> scanl (+) 0 [3,5,2,1]
[0,3,8,10,11]
ghci> scanr (+) 0 [3,5,2,1]
[11,8,3,1,0]
ghci> scanl1 (\acc x -> if x > acc then x else acc) [3,4,5,3,7,9,2,1]
[3,4,5,5,7,9,9,9]
ghci> scanl (flip (:)) [] [3,2,1]
[[],[3],[2,3],[1,2,3]]Ao usar um scanl, o resultado final estará no último
elemento da lista resultante, enquanto um scanr colocará o
resultado na cabeça.
As varreduras (scans) são usadas para monitorar a progressão de uma
função que pode ser implementada como uma dobra. Vamos nos responder a
esta pergunta: quantos elementos são necessários para a soma das
raízes quadradas de todos os números naturais exceder 1000?
Para obter as raízes quadradas de todos os números naturais, apenas
fazemos map sqrt [1..]. Agora, para obter a soma,
poderíamos fazer uma dobra, mas como estamos interessados em como a soma
progride, faremos uma varredura. Depois de fazermos a varredura, apenas
vemos quantas somas estão abaixo de 1000. A primeira soma na lista de
varredura será 1, normalmente. A segunda será 1 mais a raiz quadrada de
2. A terceira será isso mais a raiz quadrada de 3. Se houver X somas
abaixo de 1000, serão necessários X+1 elementos para que a soma exceda
1000.
sqrtSums :: Int
sqrtSums = length (takeWhile (<1000) (scanl1 (+) (map sqrt [1..]))) + 1ghci> sqrtSums
131
ghci> sum (map sqrt [1..131])
1005.0942035344083
ghci> sum (map sqrt [1..130])
993.6486803921487Usamos takeWhile aqui em vez de filter
porque filter não funciona em listas infinitas. Embora
saibamos que a lista é ascendente, filter não sabe, então
usamos takeWhile para cortar a lista de varredura na
primeira ocorrência de uma soma superior a 1000.
Aplicação de função com $
Tudo bem, em seguida, daremos uma olhada na função $,
também chamada de aplicação de função. Antes de tudo, vamos
verificar como ela é definida:
($) :: (a -> b) -> a -> b
f $ x = f x
Que diabos? O que é esse operador inútil? É apenas aplicação de
função! Bem, quase, mas não exatamente! Considerando que a aplicação
normal da função (colocar um espaço entre duas coisas) tem uma
precedência realmente alta, a função $ tem a menor
precedência. A aplicação de função com espaço é associativa à esquerda
(então f a b c é o mesmo que ((f a) b) c)), a
aplicação de função com $ é associativa à direita.
Isso é tudo muito bom, mas como isso nos ajuda? Na maioria das vezes,
é uma função de conveniência para que não tenhamos que escrever tantos
parênteses. Considere a expressão sum (map sqrt [1..130]).
Como $ tem uma precedência tão baixa, podemos reescrever
essa expressão como sum $ map sqrt [1..130], economizando
preciosas teclas! Quando um $ é encontrado, a expressão à
sua direita é aplicada como o parâmetro para a função à esquerda. Que
tal sqrt 3 + 4 + 9? Isso soma 9, 4 e a raiz quadrada de 3.
Se quisermos obter a raiz quadrada de 3 + 4 + 9, teríamos que
escrever sqrt (3 + 4 + 9) ou, se usarmos $,
podemos escrevê-lo como sqrt $ 3 + 4 + 9 porque
$ tem a menor precedência de qualquer operador. É por isso
que você pode imaginar um $ sendo o equivalente a escrever
um parêntese de abertura e depois escrever um de fechamento no extremo
direito da expressão.
Que tal sum (filter (> 10) (map (*2) [2..10]))? Bem,
como $ é associativo à direita, f (g (z x)) é
igual a f $ g $ z x. E assim, podemos reescrever
sum (filter (> 10) (map (*2) [2..10])) como
sum $ filter (> 10) $ map (*2) [2..10].
Mas, além de se livrar dos parênteses, $ significa que a
aplicação da função pode ser tratada como outra função. Dessa forma,
podemos, por exemplo, mapear a aplicação da função sobre uma lista de
funções.
ghci> map ($ 3) [(4+), (10*), (^2), sqrt]
[7.0,30.0,9.0,1.7320508075688772]Composição de função
Na matemática, a composição de função é definida assim: 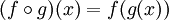 , significando que a composição de duas
funções produz uma nova função que, quando chamada com um parâmetro,
digamos, x é o equivalente a chamar g com o parâmetro
x e depois chamar o f com esse resultado.
, significando que a composição de duas
funções produz uma nova função que, quando chamada com um parâmetro,
digamos, x é o equivalente a chamar g com o parâmetro
x e depois chamar o f com esse resultado.
No Haskell, a composição da função é praticamente a mesma coisa.
Fazemos a composição da função com a função ., que é
definida assim:
(.) :: (b -> c) -> (a -> b) -> a -> c
f . g = \x -> f (g x)
Cuidado com a declaração de tipo. f deve receber como
parâmetro um valor que tenha o mesmo tipo que o valor de retorno de
g. Portanto, a função resultante pega um parâmetro do mesmo
tipo que g aceita e retorna um valor do mesmo tipo que
f retorna. A expressão negate . (* 3) retorna
uma função que pega um número, o multiplica por 3 e depois o nega.
Um dos usos da composição de funções é criar funções em tempo real para passar para outras funções. Claro, pode usar lambdas para isso, mas muitas vezes, a composição da função é mais clara e concisa. Digamos que temos uma lista de números e queremos transformar todos eles em números negativos. Uma maneira de fazer isso seria obter o valor absoluto de cada número e depois negá-lo, assim:
ghci> map (\x -> negate (abs x)) [5,-3,-6,7,-3,2,-19,24]
[-5,-3,-6,-7,-3,-2,-19,-24]Observe o lambda e como ele se parece com a composição da função resultante. Usando a composição da função, podemos reescrever isso como:
ghci> map (negate . abs) [5,-3,-6,7,-3,2,-19,24]
[-5,-3,-6,-7,-3,-2,-19,-24]Fabuloso! A composição da função é associativa à direita, para que
possamos compor muitas funções ao mesmo tempo. A expressão
f (g (z x)) é equivalente a (f . g . z) x. Com
isso em mente, podemos transformar
ghci> map (\xs -> negate (sum (tail xs))) [[1..5],[3..6],[1..7]]
[-14,-15,-27]em
ghci> map (negate . sum . tail) [[1..5],[3..6],[1..7]]
[-14,-15,-27]Mas e as funções que aceitam vários parâmetros? Bem, se quisermos
usá-las na composição de funções, geralmente temos que aplicá-las
parcialmente apenas o suficiente para que cada função aceite apenas um
parâmetro. sum (replicate 5 (max 6.7 8.9)) pode ser
reescrito como (sum . replicate 5 . max 6.7) 8.9 ou como
sum . replicate 5 . max 6.7 $ 8.9. O que acontece aqui é o
seguinte: uma função que pega o que max 6.7 pega e aplica
replicate 5 a ele é criada. Em seguida, é criada uma função
que pega o resultado disso e faz uma soma. Finalmente, essa função é
chamada com 8.9. Mas normalmente, você apenas lê isso como:
aplique 8.9 a max 6.7, depois aplique
replicate 5 a isso e depois aplique sum a
isso. Se você quiser reescrever uma expressão com muitos parênteses
usando composição de função, pode começar colocando o último parâmetro
da função mais interna após um $ e depois apenas compor
todas as outras chamadas de função, escrevendo-as sem o último parâmetro
e colocando pontos entre elas. Se você tiver
replicate 100 (product (map (*3) (zipWith max [1,2,3,4,5] [4,5,6,7,8]))),
você pode escrevê-lo como
replicate 100 . product . map (*3) . zipWith max [1,2,3,4,5] $ [4,5,6,7,8].
Se a expressão terminar com três parênteses, é provável que, se você a
traduzir em composição de função, ela terá três operadores de
composição.
Outro uso comum da composição de funções é definir funções no chamado estilo point free (também chamado de estilo pointless). Tomemos por exemplo esta função que escrevemos anteriormente:
sum' :: (Num a) => [a] -> a
sum' xs = foldl (+) 0 xsO xs é exposto em ambos os lados, certo? Por causa do
currying, podemos omitir o xs em ambos os lados, porque
chamar foldl (+) 0 cria uma função que aceita uma lista.
Escrever a função como sum' = foldl (+) 0 é chamado de
escrevê-la no estilo point free. Como escreveríamos isso no estilo point
free?
fn x = ceiling (negate (tan (cos (max 50 x))))Não podemos simplesmente nos livrar do x nos dois lados
direitos. O x no corpo da função tem parênteses depois
dele. cos (max 50) não faria sentido. Você não pode obter o
cosseno de uma função. O que podemos fazer é expressar fn
como uma composição de funções.
fn = ceiling . negate . tan . cos . max 50Excelente!
Muitas vezes, um estilo point free é mais legível e conciso, porque faz você pensar em funções e em que tipo de funções compô-las resulta, em vez de pensar em dados e como eles são embaralhados. Você pode pegar funções simples e usar a composição como cola para formar funções mais complexas. No entanto, muitas vezes, escrever uma função no estilo point free pode ser menos legível se uma função for muito complexa. É por isso que fazer longas cadeias de composição de funções é desencorajado, embora eu me declare culpado de às vezes ser muito feliz com a composição. O estilo preferido é usar ligações let para dar rótulos aos resultados intermediários ou dividir o problema em subproblemas e depois montá-lo para que a função faça sentido para alguém lendo-a, em vez de apenas fazer uma enorme cadeia de composição.
Na seção sobre maps e filters, resolvemos um problema de encontrar a soma de todos os quadrados ímpares menores que 10.000. Aqui está a aparência da solução quando colocada em uma função.
oddSquareSum :: Integer
oddSquareSum = sum (takeWhile (<10000) (filter odd (map (^2) [1..])))Sendo um fã de composição de funções, eu provavelmente teria escrito assim:
oddSquareSum :: Integer
oddSquareSum = sum . takeWhile (<10000) . filter odd . map (^2) $ [1..]No entanto, se houvesse uma chance de outra pessoa ler esse código, eu o teria escrito assim:
oddSquareSum :: Integer
oddSquareSum =
let oddSquares = filter odd $ map (^2) [1..]
belowLimit = takeWhile (<10000) oddSquares
in sum belowLimitNão ganharia nenhuma competição de “code golf”, mas alguém lendo a função provavelmente achará mais fácil de ler do que uma cadeia de composição.