Resolvendo Problemas Funcionalmente (Functionally Solving Problems)
Neste capítulo, examinaremos alguns problemas interessantes e como pensar funcionalmente para resolvê-los da maneira mais elegante possível. Provavelmente não introduziremos novos conceitos, apenas vamos flexionar nossos músculos Haskell recém-adquiridos e praticar nossas habilidades de codificação. Cada seção apresentará um problema diferente. Primeiro, descreveremos o problema, e depois tentaremos descobrir qual é a melhor (ou a menos pior) maneira de resolvê-lo.
Calculadora de Notação Polonesa Reversa (Reverse Polish notation calculator)
Normalmente, quando escrevemos expressões matemáticas na escola,
escrevemos de maneira infixa. Por exemplo, escrevemos
10 - (4 + 3) * 2. +, * e
- são operadores infixos, assim como as funções infixas que
conhecemos em Haskell (+, `elem`, etc.). Isso
o torna útil porque nós, humanos, podemos analisar (parse) facilmente em
nossas mentes, olhando para essa expressão. A desvantagem disso é que
precisamos usar parênteses para denotar precedência.
Notação
Polonesa Reversa (RPN) é outra maneira de escrever expressões
matemáticas. Inicialmente, parece um pouco estranho, mas na verdade é
muito fácil de entender e usar, porque não há necessidade de parênteses
e é muito fácil de colocar em uma calculadora. Enquanto a maioria das
calculadoras modernas usa notação infixa, algumas pessoas ainda juram
por calculadoras RPN. É assim que a expressão infixa anterior se parece
em RPN: 10 4 3 + 2 * -. Como calculamos qual é o resultado
disso? Bem, pense em uma pilha (stack). Você percorre a expressão da
esquerda para a direita. Cada vez que um número é encontrado, empurre-o
(push) para a pilha. Quando encontramos um operador, pegue os dois
números que estão no topo da pilha (também dizemos que os retiramos ou
pop), use o operador nesses dois e empurre o número resultante
de volta para a pilha. Ao chegar ao final da expressão, você deve ficar
com um único número se a expressão foi bem formada e esse número
representa o resultado.
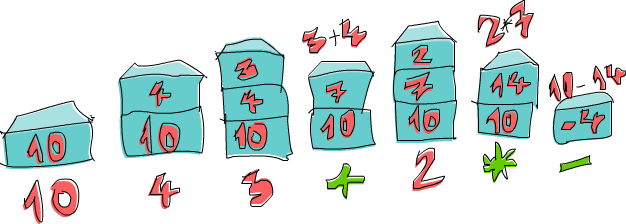
Vamos passar pela expressão 10 4 3 + 2 * - juntos!
Primeiro, empurramos 10 para a pilha e a pilha agora é
10. O próximo item é 4, então o empurramos
também para a pilha. A pilha agora é 10, 4. Fazemos o mesmo
com o 3 e a pilha agora é 10, 4, 3. E agora
encontramos um operador, ou seja, +! Retiramos (pop) os
dois números superiores da pilha (agora a pilha é apenas
10), adicionamos esses números juntos e empurramos esse
resultado para a pilha. A pilha agora é 10, 7. Empurramos
2 para a pilha, a pilha por enquanto é
10, 7, 2. Encontramos um operador novamente, então vamos
retirar 7 e 2 da pilha, multiplicá-los e
empurrar o resultado para a pilha. Multiplicar 7 por
2 produz um 14, então a pilha que temos agora
é 10, 14. Finalmente, há um -. Retiramos
10 e 14 da pilha, subtraímos 14
de 10 e empurramos isso de volta. O número na pilha agora é
-4 e, como não há mais números ou operadores em nossa
expressão, esse é o nosso resultado!
Agora que sabemos como calcularíamos qualquer expressão RPN à mão,
vamos pensar em como poderíamos fazer uma função Haskell que tome como
parâmetro uma string que contém uma expressão RPN, como
"10 4 3 + 2 * -", e nos devolve seu resultado.
Qual seria o tipo dessa função? Queremos que seja necessária uma
string como parâmetro e produza um número como resultado. Portanto,
provavelmente será algo como
solveRPN :: (Num a) => String -> a.
Dica profissional: Ajuda muito pensar primeiro qual deve ser a declaração de tipo de uma função antes de nos preocuparmos com a implementação e depois anotá-lá. Em Haskell, a declaração de tipo de uma função nos diz muito sobre a função, devido ao sistema de tipos muito forte.

Legal. Ao implementar uma solução para um problema em Haskell, também
é bom pensar em como você fez à mão e talvez tente ver se consegue obter
alguma percepção disso. Aqui vemos que tratamos cada número ou operador
que foi separado por um espaço como um único item. Portanto, pode nos
ajudar se começarmos quebrando uma string como
"10 4 3 + 2 * -" em uma lista de itens como
["10","4","3","+","2","*","-"].
Em seguida, o que fizemos com essa lista de itens em nossa cabeça? Nós passamos por ela da esquerda para a direita e mantivemos uma pilha enquanto fazíamos isso. A frase anterior te lembra alguma coisa? Lembre-se, na seção sobre folds, dissemos que praticamente qualquer função em que você percorre uma lista da esquerda para a direita ou da direita para a esquerda, elemento por elemento, e constrói (acumula) algum resultado (seja um número, uma lista, uma pilha, o que for) pode ser implementado com um fold.
Neste caso, vamos usar um fold esquerdo (left fold), porque passamos pela lista da esquerda para a direita. O valor do acumulador será nossa pilha e, portanto, o resultado do fold também será uma pilha, apenas como vimos, terá apenas um item.
Mais uma coisa a se pensar é: bem, como vamos representar a pilha?
Proponho que usemos uma lista. Também proponho que mantenhamos o topo da
nossa pilha no head (cabeça) da lista. Isso ocorre porque
adicionar à cabeça (início) de uma lista é muito mais rápido do que
adicionar ao final dela. Portanto, se tivermos uma pilha de, digamos,
10, 4, 3, representaremos isso como a lista
[3,4,10].
Agora temos informações suficientes para esboçar nossa função. Vai
levar uma string, como "10 4 3 + 2 * -" e quebrá-la em uma
lista de itens usando words para obter
["10","4","3","+","2","*","-"]. Em seguida, faremos um fold
esquerdo sobre essa lista e terminaremos com uma pilha que tem um único
item, então [-4]. Tiramos esse único item da lista e esse é
o nosso resultado final!
Então, aqui está um esboço dessa função:
import Data.List
solveRPN :: (Num a) => String -> a
solveRPN expression = head (foldl foldingFunction [] (words expression))
where foldingFunction stack item = ...Pegamos a expressão e a transformamos em uma lista de itens. Então
fazemos o fold sobre essa lista de itens com a função de dobra
(foldingFunction). Cuidado com o [], que
representa o acumulador inicial. O acumulador é a nossa pilha, então
[] representa uma pilha vazia, que é com o que começamos.
Depois de obter a pilha final com um único item, chamamos
head nessa lista para retirar o item e depois aplicamos
read. Espere, na verdade, nós apenas chamamos
head, read será usado dentro da nossa função
de dobra para converter strings em números.
Então, tudo o que resta agora é implementar uma função de dobra que
levará uma pilha, como [4,10], e um item, como
"3", e retornará uma nova pilha [3,4,10]. Se a
pilha for [4,10] e o item "*", então terá que
retornar [40]. Mas, antes disso, vamos transformar nossa
função em estilo livre
de pontos (point-free style), porque tem muitos parênteses que estão
me assustando:
import Data.List
solveRPN :: (Num a) => String -> a
solveRPN = head . foldl foldingFunction [] . words
where foldingFunction stack item = ...Ah, aí vamos nós. Muito melhor. Portanto, a função de dobra levará
uma pilha e um item e retornará uma nova pilha. Usaremos correspondência
de padrões (pattern matching) para obter os itens do topo de uma pilha e
corresponder aos operadores como "*" e
"-".
solveRPN :: (Num a, Read a) => String -> a
solveRPN = head . foldl foldingFunction [] . words
where foldingFunction (x:y:ys) "*" = (x * y):ys
foldingFunction (x:y:ys) "+" = (x + y):ys
foldingFunction (x:y:ys) "-" = (y - x):ys
foldingFunction xs numberString = read numberString:xsNós estabelecemos isso como quatro padrões. Os padrões serão tentados
de cima para baixo. Primeiro, a função de dobra verá se o item atual é
"* ". Se for, levará uma lista como [3,4,9,3]
e chamará seus dois primeiros elementos de x e
y, respectivamente. Portanto, neste caso, x
seria 3 e y seria 4.
ys seria [9,3]. Ele retornará uma lista que é
exatamente igual a ys, apenas tem x e
y multiplicados como sua cabeça. Então, com isso, retiramos
os dois números mais altos da pilha, multiplicamos e empurramos o
resultado de volta para a pilha. Se o item não for "* ", a
correspondência de padrões cairá e "+" será verificado e
assim por diante.
Se o item não for nenhum dos operadores, assumimos que é uma string
que representa um número. Se for um número, apenas chamamos
read nessa string para obter um número dela e retornar a
pilha anterior, mas com esse número empurrado para o topo.
E é isso! Também notamos que adicionamos uma restrição de classe
extra de Read a à declaração de tipo, porque chamamos
read em nossa string para obter o número. Portanto, essa
declaração significa que o resultado pode ser de qualquer tipo que faça
parte das classes de tipo Num e Read (como
Int, Float, etc.).
Para a lista de itens ["2","3","+"], nossa função
começará dobrando (folding) a partir da esquerda. A pilha inicial será
[]. Ele chamará a função de dobra com [] como
a pilha (acumulador) e "2" como o item. Como esse item não
é um operador, ele será read (lido) e o adicionado ao
início de []. Portanto, a nova pilha agora é
[2] e a função de dobra será chamada com [2]
como a pilha e ["3"] como o item, produzindo uma nova pilha
de [3,2]. Então, é chamado pela terceira vez com
[3,2] como a pilha e "+" como o item. Isso faz
com que esses dois números sejam retirados da pilha, somados e
empurrados de volta. A pilha final é [5], que é o número
que retornamos.
Vamos brincar com a nossa função:
ghci> solveRPN "10 4 3 + 2 * -"
-4
ghci> solveRPN "2 3 +"
5
ghci> solveRPN "90 34 12 33 55 66 + * - +"
-3947
ghci> solveRPN "90 34 12 33 55 66 + * - + -"
4037
ghci> solveRPN "90 34 12 33 55 66 + * - + -"
4037
ghci> solveRPN "90 3 -"
87Legal, funciona! Uma coisa boa dessa função é que ela pode ser
facilmente modificada para suportar vários outros operadores. Eles nem
precisam ser operadores binários. Por exemplo, podemos criar um operador
"log" que apenas retira um número da pilha e empurra de
volta seu logaritmo. Também podemos criar operadores ternários que
retiram três números da pilha e empurram de volta um resultado ou
operadores como "sum" que retiram todos os números e
empurram de volta sua soma.
Vamos modificar nossa função para receber mais alguns operadores. Por
uma questão de simplicidade, alteraremos sua declaração de tipo para que
ela retorne um número do tipo Float.
import Data.List
solveRPN :: String -> Float
solveRPN = head . foldl foldingFunction [] . words
where foldingFunction (x:y:ys) "*" = (x * y):ys
foldingFunction (x:y:ys) "+" = (x + y):ys
foldingFunction (x:y:ys) "-" = (y - x):ys
foldingFunction (x:y:ys) "/" = (y / x):ys
foldingFunction (x:y:ys) "^" = (y ** x):ys
foldingFunction (x:xs) "ln" = log x:xs
foldingFunction xs "sum" = [sum xs]
foldingFunction xs numberString = read numberString:xsUau, ótimo! / é divisão, é claro, e ** é a
exponenciação de ponto flutuante. Com o operador de logaritmo, apenas
combinamos padrões com um único elemento e o restante da pilha, porque
precisamos apenas de um elemento para executar seu logaritmo natural.
Com o operador de soma, apenas retornamos uma pilha que possui apenas um
elemento, que é a soma da pilha até agora.
ghci> solveRPN "2.7 ln"
0.9932518
ghci> solveRPN "10 10 10 10 sum 4 /"
10.0
ghci> solveRPN "10 10 10 10 10 sum 4 /"
12.5
ghci> solveRPN "10 2 ^"
100.0Observe que podemos incluir números de ponto flutuante em nossa
expressão, porque read sabe como lê-los.
ghci> solveRPN "43.2425 0.5 ^"
6.575903Eu acho que fazer uma função que possa calcular expressões RPN arbitrárias de ponto flutuante e tem a opção de ser facilmente estendida em 10 linhas é incrível.
Uma coisa a observar sobre essa função é que ela não é realmente
tolerante a falhas. Quando recebe uma entrada que não faz sentido, ela
apenas trava tudo. Faremos uma versão tolerante a falhas com uma
declaração de tipo de solveRPN :: String -> Maybe Float
assim que conhecermos mônadas (elas não são assustadoras, confie em
mim!). Poderíamos fazer uma agora, mas seria um pouco entediante, porque
envolveria muita verificação de Nothing em cada etapa. Se
você está se sentindo pronto para o desafio, pode ir em frente e tentar!
Dica: você pode usar reads para ver se uma leitura foi
bem-sucedida ou não.
Heathrow para Londres (Heathrow to London)
O nosso próximo problema é o seguinte: seu avião acabou de pousar na Inglaterra e você alugou um carro. Você tem uma reunião muito em breve e precisa ir do Aeroporto de Heathrow para Londres o mais rápido possível (mas com segurança!).
Existem duas estradas principais indo de Heathrow para Londres e há várias estradas regionais que as cruzam. Leva uma quantidade fixa de tempo para viajar de um cruzamento para outro. Cabe a você encontrar o caminho ideal para que você chegue a Londres o mais rápido possível! Você começa no lado esquerdo e pode atravessar para a outra estrada principal ou seguir em frente.
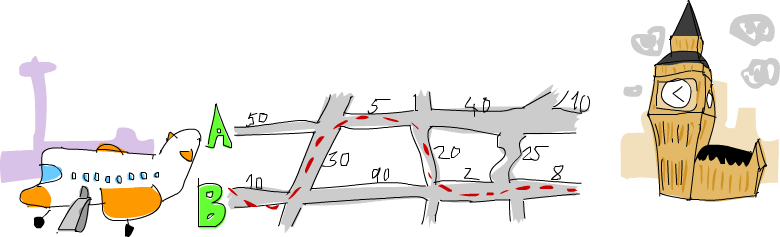
Como você pode ver na imagem, o caminho mais curto de Heathrow para Londres, neste caso, é começar na estrada principal B, atravessar, seguir em frente em A, atravessar novamente e seguir em frente duas vezes em B. Se tomarmos esse caminho, leva 75 minutos. Se tivéssemos escolhido qualquer outro caminho, levaria mais do que isso.
Nosso trabalho é fazer um programa que receba uma entrada que represente um sistema rodoviário e imprima qual é o caminho mais curto através dele. Aqui está a aparência da entrada para este caso:
50
10
30
5
90
20
40
2
25
10
8
0Para analisar mentalmente o arquivo de entrada, leia-o de três em três e divida mentalmente o sistema rodoviário em seções. Cada seção é composta por estrada A, estrada B e uma estrada de cruzamento. Para que ele se encaixe perfeitamente em três, dizemos que há uma última seção de cruzamento que leva 0 minutos para atravessar. Isso ocorre porque não nos importamos onde chegamos em Londres, desde que estejamos em Londres.
Assim como fizemos ao resolver o problema da calculadora RPN, vamos resolver esse problema em três etapas:
- Esqueça Haskell por um minuto e pense em como resolveríamos o problema à mão.
- Pense em como vamos representar nossos dados em Haskell.
- Descubra como operar com esses dados em Haskell para que produzamos uma solução.
Na seção de calculadora RPN, primeiro descobrimos que, ao calcular uma expressão à mão, manteríamos uma espécie de pilha em nossas mentes e depois passaríamos pela expressão um item de cada vez. Decidimos usar uma lista de strings para representar nossa expressão. Finalmente, usamos um fold esquerdo para percorrer a lista de strings, mantendo uma pilha para produzir uma solução.
Ok, então como descobriríamos o caminho mais curto de Heathrow para Londres à mão? Bem, podemos apenas olhar para toda a imagem e tentar adivinhar qual é o caminho mais curto e espero que façamos um palpite certo. Essa solução funciona para entradas muito pequenas, mas e se tivermos uma estrada que tenha 10.000 seções? Caramba! Também não poderemos dizer com certeza que nossa solução é a ideal, podemos apenas dizer que temos certeza.
Essa não é uma boa solução então. Aqui está uma imagem simplificada do nosso sistema rodoviário:
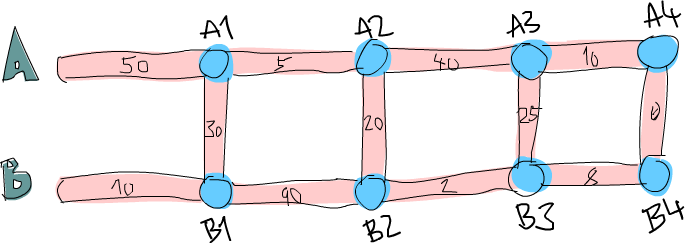
Tudo bem, você consegue descobrir qual é o caminho mais curto para o primeiro cruzamento (o primeiro ponto azul em A, marcado como A1) na estrada A? Isso é bastante trivial. Apenas vemos se é mais curto ir diretamente para a frente em A ou se é mais curto avançar em B e depois atravessar. Obviamente, é mais barato avançar via B e depois atravessar porque isso leva 40 minutos, enquanto indo diretamente via A leva 50 minutos. E o cruzamento B1? Mesma coisa. Vemos que é muito mais barato ir diretamente via B (incorrendo em um custo de 10 minutos), porque ir via A e depois cruzar nos levaria 80 minutos!
Agora sabemos qual é o caminho mais barato para A1 (vá via B
e depois atravesse, então diremos que é B, C com um custo
de 40) e sabemos qual é o caminho mais barato para B1 (vá
diretamente via B, então é apenas B, indo a 10). Esse
conhecimento nos ajuda se quisermos conhecer o caminho mais barato para
o próximo cruzamento nas duas estradas principais? Caramba, com certeza
sim!
Vamos ver qual seria o caminho mais curto para A2. Para
chegar a A2, iremos diretamente para A2 a partir de
A1 ou avançaremos de B1 e depois cruzaremos
(lembre-se, só podemos seguir em frente ou atravessar para o outro
lado). E porque sabemos o custo para A1 e B1, podemos
descobrir facilmente qual é o melhor caminho para A2. Custa 40
para chegar a A1 e depois 5 para chegar de A1 a
A2, então é B, C, A por um custo de 45. Custa
apenas 10 para chegar a B1, mas depois levaria 110 minutos
adicionais para ir para B2 e depois atravessar! Então,
obviamente, o caminho mais barato para A2 é
B, C, A.
Da mesma forma, a maneira mais barata de B2 é avançar de A1 e depois atravessar.
Talvez você esteja se perguntando: mas e a chegar a A2 cruzando primeiro em B1 e depois seguindo em frente? Bem, já cobrimos a travessia de B1 para A1 quando estávamos procurando a melhor maneira de A1, então não precisamos levar isso em consideração na próxima etapa também.
Agora que temos o melhor caminho para A2 e B2, podemos repetir isso indefinidamente até chegarmos ao fim. Depois de obtermos os melhores caminhos para A4 e B4, o que for mais barato é o caminho ideal!
Portanto, em essência, para a segunda seção, apenas repetimos a etapa que fizemos a princípio, apenas levamos em consideração os melhores caminhos anteriores em A e B. Poderíamos dizer que também levamos em consideração os melhores caminhos em A e em B na primeira etapa, mas ambos eram caminhos vazios com um custo de 0.
Aqui está um resumo. Para obter o melhor caminho de Heathrow para Londres, fazemos isso: primeiro vemos qual é o melhor caminho para o próximo cruzamento na estrada principal A. As duas opções estão indo diretamente para a frente ou começando na estrada oposta, avançando e depois atravessando. Lembramos o custo e o caminho. Usamos o mesmo método para ver qual é o melhor caminho para o próximo cruzamento na estrada principal B e lembrar disso. Em seguida, vemos se o caminho para o próximo cruzamento em A é mais barato se formos do cruzamento A anterior ou se formos do cruzamento B anterior e, em seguida, atravessarmos. Lembramos o caminho mais barato e depois fazemos o mesmo para o cruzamento oposto a ele. Fazemos isso para todas as seções até chegarmos ao fim. Quando chegarmos ao fim, o mais barato dos dois caminhos que temos é o nosso caminho ideal!
Portanto, em essência, mantemos um caminho mais curto na estrada A e um caminho mais curto na estrada B e, quando chegamos ao fim, o menor desses dois é o nosso caminho. Agora sabemos como descobrir o caminho mais curto à mão. Se você tivesse tempo, papel e lápis suficientes, poderia descobrir o caminho mais curto através de um sistema rodoviário com qualquer número de seções.
Próximo passo! Como representamos esse sistema rodoviário com os tipos de dados de Haskell? Uma maneira é pensar nos pontos de partida e cruzamentos como nós de um gráfico que apontam para outros cruzamentos. Se imaginarmos que os pontos de partida realmente apontam um para o outro com uma estrada que tem um comprimento de um, vemos que cada cruzamento (ou nó) aponta para o nó do outro lado e também para o próximo do seu lado. Exceto pelos últimos nós, eles apenas apontam para o outro lado.
data Node = Node Road Road | EndNode Road
data Road = Road Int NodeUm nó é um nó normal e possui informações sobre a estrada que leva à
outra estrada principal e a estrada que leva ao próximo nó ou um nó
final, que só tem informações sobre a estrada para a outra estrada
principal. Uma estrada mantém informações sobre quanto tempo é e qual nó
aponta. Por exemplo, a primeira parte da estrada na estrada principal A
seria Road 50 a1 onde a1 seria um nó
Node x y, onde x e y são estradas
que apontam para B1 e A2.
Outra maneira seria usar Maybe para as partes da estrada
que apontam para a frente. Cada nó tem uma parte da estrada que aponta
para a estrada oposta, mas apenas os nós que não são os finais têm peças
de estrada que apontam para a frente.
data Node = Node Road (Maybe Road)
data Road = Road Int NodeEssa é uma maneira correta de representar o sistema rodoviário em
Haskell e certamente poderíamos resolver esse problema com ele, mas
talvez pudéssemos criar algo mais simples? Se pensarmos em nossa solução
à mão, sempre verificamos os comprimentos de três partes da estrada ao
mesmo tempo: a parte da estrada na estrada A, sua parte oposta na
estrada B e parte C, que toca as duas partes e as conecta. Quando
procurávamos o caminho mais curto para A1 e B1,
tínhamos apenas que lidar com o comprimento das três primeiras partes,
que têm comprimentos de 50, 10 e 30. Vamos chamar isso de uma seção.
Portanto, o sistema rodoviário que usamos para este exemplo pode ser
facilmente representado como quatro seções: 50, 10, 30,
5, 90, 20, 40, 2, 25 e
10, 8, 0.
É sempre bom manter nossos tipos de dados o mais simples possível, embora não mais simples!
data Section = Section { getA :: Int, getB :: Int, getC :: Int } deriving (Show)
type RoadSystem = [Section]Isso é praticamente perfeito! É o mais simples possível e tenho a sensação de que funcionará perfeitamente para implementar nossa solução.
Section é um tipo de dado algébrico simples que contém
três números inteiros para os comprimentos de suas três partes da
estrada. Introduzimos um sinônimo de tipo também, dizendo que
RoadSystem é uma lista de seções.
Poderíamos também usar uma tripla de (Int, Int, Int)
para representar uma seção de estrada. O uso de tuplas em vez de criar
seus próprios tipos de dados algébricos é bom para algumas coisas
localizadas pequenas, mas geralmente é melhor criar um novo tipo para
coisas assim. Dá ao sistema de tipos mais informações sobre o que é o
quê. Podemos usar (Int, Int, Int) para representar uma
seção de estrada ou um vetor no espaço 3D e podemos operar nesses dois,
mas isso nos permite misturá-los. Se usarmos tipos de dados
Section e Vector, não podemos acidentalmente
adicionar um vetor a uma seção de um sistema viário.
Nosso sistema rodoviário de Heathrow para Londres agora pode ser representado assim:
heathrowToLondon :: RoadSystem
heathrowToLondon = [Section 50 10 30, Section 5 90 20, Section 40 2 25, Section 10 8 0]Tudo o que precisamos fazer agora é implementar a solução que criamos
anteriormente em Haskell. Qual deve ser a declaração de tipo para uma
função que calcula um caminho mais curto para qualquer sistema
rodoviário? Ele deve levar um sistema rodoviário como um parâmetro e
retornar um caminho. Representaremos um caminho como uma lista também.
Vamos introduzir um tipo Label que é apenas uma enumeração
de A, B ou C. Também faremos um
sinônimo de tipo: Path.
data Label = A | B | C deriving (Show)
type Path = [(Label, Int)]Nossa função, vamos chamá-la de optimalPath, deve ter
uma declaração de tipo de
optimalPath :: RoadSystem -> Path. Se chamado com o
sistema viário heathrowToLondon, deve retornar o seguinte
caminho:
[(B,10),(C,30),(A,5),(C,20),(B,2),(B,8)]Vamos ter que percorrer a lista com as seções da esquerda para a direita e manter o caminho ideal em A e o caminho ideal em B à medida que avançamos. Acumularemos o melhor caminho enquanto caminhamos sobre a lista, esquerda para a direita. O que isso soa? Ding, ding, ding! Isso mesmo, um LEFT FOLD!
Ao fazer a solução à mão, houve um passo que repetimos repetidamente.
Isso envolveu a verificação dos caminhos ideais em A e B até agora e a
seção atual para produzir os novos caminhos ideais em A e B. Por
exemplo, no início, os caminhos ideais eram [] e
[] para A e B, respectivamente. Examinamos a seção
Section 50 10 30 e concluímos que o novo caminho ideal para
A1 é [(B,10),(C,30)] e o caminho ideal para
B1 é [(B,10)]. Se você olhar para esta etapa como
uma função, é necessário um par de caminhos e uma seção e produz um novo
par de caminhos. O tipo é
(Path, Path) -> Section -> (Path, Path). Vamos em
frente e implementar essa função, porque ela deve ser útil.
Dica: será útil porque
(Path, Path) -> Section -> (Path, Path) pode ser
usada como a função binária para um fold esquerdo, que deve ter um tipo
de a -> b -> a
roadStep :: (Path, Path) -> Section -> (Path, Path)
roadStep (pathA, pathB) (Section a b c) =
let priceA = sum $ map snd pathA
priceB = sum $ map snd pathB
forwardPriceToA = priceA + a
crossPriceToA = priceB + b + c
forwardPriceToB = priceB + b
crossPriceToB = priceA + a + c
newPathToA = if forwardPriceToA <= crossPriceToA
then (A,a):pathA
else (C,c):(B,b):pathB
newPathToB = if forwardPriceToB <= crossPriceToB
then (B,b):pathB
else (C,c):(A,a):pathA
in (newPathToA, newPathToB)
O que está acontecendo aqui? Primeiro, calcule o preço ideal na
estrada A com base no melhor até agora em A e fazemos o mesmo para B.
Nós fazemos sum $ map snd pathA, então se
pathA é algo como [(A,100),(C,20)],
priceA torna-se 120.
forwardPriceToA é o preço que pagaríamos se fôssemos para o
próximo cruzamento em A se formos para lá diretamente do cruzamento A
anterior. É igual ao melhor preço para o nosso A anterior, mais o
comprimento da parte A da seção atual. crossPriceToA é o
preço que pagaríamos se fôssemos para a próxima A avançando da B
anterior e depois cruzando. É o melhor preço para a B anterior até
agora, mais o comprimento B da seção mais o comprimento C da seção.
Determinamos forwardPriceToB e
crossPriceToB da mesma maneira.
Agora que sabemos qual é o melhor caminho para A e B, só precisamos
fazer os novos caminhos para A e B com base nisso. Se for mais barato ir
para A apenas avançando, definimos newPathToA para ser
(A,a):pathA. Basicamente, precedemos o Label
A e a seção comprimento a para o caminho ideal
no caminho em A até agora. Basicamente, dizemos que o melhor caminho
para o próximo cruzamento A é o caminho para o cruzamento A anterior e
depois uma seção para a frente via A. Lembre-se, A é apenas
um rótulo, enquanto a tem um tipo de Int. Por
que precedemos (prepend) em vez de fazer pathA ++ [(A,a)]?
Bem, adicionar um elemento ao início de uma lista (também conhecido como
consing) é muito mais rápido do que adicioná-lo ao final. Isso significa
que o caminho será o caminho errado depois de dobrarmos uma lista com
essa função, mas é fácil inverter a lista posteriormente. Se for mais
barato chegar ao próximo cruzamento A avançando da estrada B e depois
cruzando, então newPathToA é o antigo caminho para B que
depois avança e atravessa para A. Fazemos a mesma coisa para
newPathToB, apenas tudo é espelhado.
Finalmente, retornamos newPathToA e
newPathToB em um par.
Vamos executar esta função na primeira seção de
heathrowToLondon. Por ser a primeira seção, os melhores
caminhos nos parâmetros A e B serão um par de listas vazias.
ghci> roadStep ([], []) (head heathrowToLondon)
([(C,30),(B,10)],[(B,10)])Lembre-se, os caminhos são revertidos, então leia-os da direita para a esquerda. A partir disso, podemos ler que o melhor caminho para a próxima A é começar em B e depois atravessar para A e que o melhor caminho para a próxima B é apenas ir diretamente para a frente do ponto de partida em B.
Dica de otimização: quando fazemos
priceA = sum $ map snd pathA, estamos calculando o preço do
caminho em cada etapa. Não precisaríamos fazer isso se implementássemos
roadStep como uma função
(Path, Path, Int, Int) -> Section -> (Path, Path, Int, Int)
onde os inteiros representam o melhor preço em A e B.
Agora que temos uma função que pega um par de caminhos e uma seção e
produz um novo caminho ideal, podemos facilmente fazer um fold esquerdo
sobre uma lista de seções. roadStep é chamado com
([],[]) e a primeira seção e retorna um par de caminhos
ideais para essa seção. Então, é chamado com esse par de caminhos e a
próxima seção e assim por diante. Quando percorremos todas as seções,
ficamos com um par de caminhos ideais e o mais curto deles é a nossa
resposta. Com isso em mente, podemos implementar
optimalPath.
optimalPath :: RoadSystem -> Path
optimalPath roadSystem =
let (bestAPath, bestBPath) = foldl roadStep ([],[]) roadSystem
in if sum (map snd bestAPath) <= sum (map snd bestBPath)
then reverse bestAPath
else reverse bestBPathNós dobramos à esquerda sobre roadSystem (lembre-se, é
uma lista de seções) com o acumulador inicial sendo um par de caminhos
vazios. O resultado desse fold é um par de caminhos, para que
correspondamos ao padrão no par para obter os caminhos em si. Então,
verificamos qual deles era mais barato e o devolvemos. Antes de
devolvê-lo, também o revertemos, porque os caminhos ideais até agora
foram revertidos devido a nós escolhermos consing em vez de
anexar (appending).
Vamos testar isso!
ghci> optimalPath heathrowToLondon
[(B,10),(C,30),(A,5),(C,20),(B,2),(B,8),(C,0)]Este é o resultado que deveríamos obter! Impressionante! Difere um
pouco do nosso resultado esperado, porque há um passo (C,0)
no final, o que significa que atravessamos para a outra estrada quando
estivermos em Londres, mas como essa travessia não custa nada, esse
ainda é o resultado correto.
Temos a função que encontra um caminho ideal com base nisso, agora só
precisamos ler uma representação textual de um sistema rodoviário da
entrada padrão, converte-a em um tipo de RoadSystem,
executar isso através de nossa função optimalPath e
imprimir o caminho.
Antes de tudo, vamos criar uma função que pegue uma lista e a divide
em grupos do mesmo tamanho. Vamos chamá-lo de groupsOf.
Para um parâmetro de [1..10], groupsOf 3 deve
retornar [[1,2,3],[4,5,6],[7,8,9],[10]].
groupsOf :: Int -> [a] -> [[a]]
groupsOf 0 _ = undefined
groupsOf _ [] = []
groupsOf n xs = take n xs : groupsOf n (drop n xs)Uma função recursiva padrão. Para um xs de
[1..10] e um n de 3, isso é igual
a [1,2,3] : groupsOf 3 [4,5,6,7,8,9,10]. Quando a recursão
termina, obtemos nossa lista em grupos de três. E aqui está nossa função
main, que lê da entrada padrão, cria um
RoadSystem fora dele e imprime o caminho mais curto:
import Data.List
main = do
contents <- getContents
let threes = groupsOf 3 (map read $ lines contents)
roadSystem = map (\[a,b,c] -> Section a b c) threes
path = optimalPath roadSystem
pathString = concat $ map (show . fst) path
pathPrice = sum $ map snd path
putStrLn $ "The best path to take is: " ++ pathString
putStrLn $ "The price is: " ++ show pathPricePrimeiro, obtemos todo o conteúdo da entrada padrão. Em seguida,
chamamos lines com nosso conteúdo para converter algo como
"50\n10\n30\n... para ["50","10","30".. e
depois mapeamos read para convertê-lo em uma lista de
números. Chamamos groupsOf 3 para que o transformemos em
uma lista de listas de comprimento 3. Mapeamos o lambda
(\[a,b,c] -> Section a b c) sobre essa lista de listas.
Como você pode ver, o lambda apenas pega uma lista de comprimento 3 e a
transforma em uma seção. Portanto, roadSystem agora é o
nosso sistema de estradas e até tem o tipo correto, ou seja,
RoadSystem (ou [Section]). Chamamos
optimalPath com isso e depois obtemos o caminho e o preço
em uma boa representação textual e imprimimos.
Nós salvamos o seguinte texto
50
10
30
5
90
20
40
2
25
10
8
0em um arquivo chamado paths.txt e depois o alimentamos
em nosso programa.
$ cat paths.txt | runhaskell heathrow.hs
The best path to take is: BCACBBC
The price is: 75Funciona como um encanto! Você pode usar seu conhecimento do módulo
Data.Random para gerar um sistema de estradas muito mais
longo, que você pode alimentar para o que acabamos de escrever. Se você
receber estouros de pilha (stack overflows), tente usar
foldl' em vez de foldl, porque
foldl' é estrito.