Começando
Preparar, apontar, já!
 Tudo bem, vamos começar! Se você é
o tipo de pessoa horrível que não lê introduções às coisas e a pulou,
talvez queira ler a última seção da introdução, porque ela explica o que
você precisa para seguir este tutorial e como vamos carregar as funções.
A primeira coisa que faremos é executar o modo interativo do GHC e
chamar alguma função para ter uma noção muito básica de Haskell. Abra
seu terminal e digite
Tudo bem, vamos começar! Se você é
o tipo de pessoa horrível que não lê introduções às coisas e a pulou,
talvez queira ler a última seção da introdução, porque ela explica o que
você precisa para seguir este tutorial e como vamos carregar as funções.
A primeira coisa que faremos é executar o modo interativo do GHC e
chamar alguma função para ter uma noção muito básica de Haskell. Abra
seu terminal e digite ghci. Você será recebido com algo
assim.
GHCi, version 9.2.4: https://www.haskell.org/ghc/ :? for help
ghci>Parabéns, você está no GHCI!
Aqui está um pouco de aritmética simples.
ghci> 2 + 15
17
ghci> 49 * 100
4900
ghci> 1892 - 1472
420
ghci> 5 / 2
2.5
ghci>Isso é bastante autoexplicativo. Também podemos usar vários operadores em uma linha e todas as regras de precedência usuais são obedecidas. Podemos usar parênteses para tornar a precedência explícita ou para alterá-la.
ghci> (50 * 100) - 4999
1
ghci> 50 * 100 - 4999
1
ghci> 50 * (100 - 4999)
-244950Muito legal, né? Sim, eu sei que não é, mas tenha paciência comigo.
Uma pequena armadilha a ser observada aqui é negar números. Se queremos
ter um número negativo, é sempre melhor cercá-lo com parênteses. Fazer
5 * -3 fará o GHCI gritar com você, mas fazer
5 * (-3) funcionará muito bem.
A álgebra booleana também é bastante direta. Como você provavelmente
sabe, && significa um booleano e (and),
|| significa um booleano ou (or). not
nega um True ou um False.
ghci> True && False
False
ghci> True && True
True
ghci> False || True
True
ghci> not False
True
ghci> not (True && True)
FalseO teste de igualdade é feito assim.
ghci> 5 == 5
True
ghci> 1 == 0
False
ghci> 5 /= 5
False
ghci> 5 /= 4
True
ghci> "hello" == "hello"
TrueQue tal fazer 5 + "llama" ou 5 == True?
Bem, se tentarmos o primeiro trecho, receberemos uma mensagem de erro
grande e assustadora!
<interactive>:1:1: error: [GHC-39999]
• No instance for ‘Num String’ arising from the literal ‘5’
• In the first argument of ‘(+)’, namely ‘5’
In the expression: 5 + "llama"
In an equation for ‘it’: it = 5 + "llama"Caramba! O que o GHCI está nos dizendo aqui é que
"llama" não é um número e, portanto, não sabe como
adicioná-lo a 5. Mesmo se não fosse "llama", mas
"four" ou "4", Haskell ainda não consideraria
isso um número. + espera que seu lado esquerdo e direito
sejam números. Se tentássemos fazer True == 5, o GHCI nos
diria que os tipos não correspondem. Considerando que +
funciona apenas em coisas consideradas números, == funciona
em quaisquer duas coisas que podem ser comparadas. Mas o problema é que
ambos têm que ser o mesmo tipo de coisa. Você não pode comparar maçãs e
laranjas. Vamos dar uma olhada nos tipos um pouco mais tarde. Nota: você
pode fazer 5 + 4.0 porque 5 é sorrateiro e
pode agir como um número inteiro ou um número de ponto flutuante.
4.0 não pode agir como um número inteiro, então
5 é quem tem que se adaptar.
Nota: Todos os erros do GHC recebem identificadores
exclusivos, como GHC-39999 acima. Sempre que você estiver
preso a um erro persistente, pode procurá-lo em https://errors.haskell.org/ para
aprender causas típicas e soluções.
Você pode não saber, mas usamos funções o tempo todo. Por exemplo,
* é uma função que pega dois números e os multiplica. Como
você viu, nós a chamamos colocando-a entre eles. Isso é o que chamamos
de função infixa. A maioria das funções que não são usadas com
números são funções prefixas. Vamos dar uma olhada nelas.
 As funções geralmente são
prefixas, portanto, a partir de agora, não declararemos explicitamente
que uma função é da forma prefixa, apenas assumiremos. Na maioria das
linguagens imperativas, as funções são chamadas escrevendo o nome da
função e, em seguida, escrevendo seus parâmetros entre parênteses,
geralmente separados por vírgulas. Em Haskell, as funções são chamadas
escrevendo o nome da função, um espaço e depois os parâmetros, separados
por espaços. Para começar, tentaremos chamar uma das funções mais chatas
do Haskell.
As funções geralmente são
prefixas, portanto, a partir de agora, não declararemos explicitamente
que uma função é da forma prefixa, apenas assumiremos. Na maioria das
linguagens imperativas, as funções são chamadas escrevendo o nome da
função e, em seguida, escrevendo seus parâmetros entre parênteses,
geralmente separados por vírgulas. Em Haskell, as funções são chamadas
escrevendo o nome da função, um espaço e depois os parâmetros, separados
por espaços. Para começar, tentaremos chamar uma das funções mais chatas
do Haskell.
ghci> succ 8
9A função succ pega qualquer coisa que tenha um sucessor
definido e retorna esse sucessor. Como você pode ver, apenas separamos o
nome da função do parâmetro com um espaço. Chamar uma função com vários
parâmetros também é simples. As funções min e
max recebem duas coisas que podem ser colocadas em uma
ordem (como números inteiros!). min retorna o que é menor e
max retorna o que é maior. Veja você mesmo:
ghci> min 9 10
9
ghci> max 100 101
101A aplicação de função (chamar uma função colocando um espaço depois dela e digitando os parâmetros) tem a maior precedência de todas. O que isso significa para nós é que essas duas declarações são equivalentes.
ghci> succ 9 + max 5 4 + 1
16
ghci> (succ 9) + (max 5 4) + 1
16No entanto, se quiséssemos obter o sucessor do produto dos números 9
e 10, não poderíamos escrever succ 9 * 10 porque isso
obteria o sucessor de 9, que seria multiplicado por 10. Então 100.
Teríamos que escrever succ (9 * 10) para obter 91.
Se uma função recebe dois parâmetros, também podemos chamá-la como
uma função infixa, cercando-a com crases. Por exemplo, a função
div pega dois inteiros e faz a divisão integral entre eles.
Fazer div 92 10 resulta em 9. Mas quando chamamos assim,
pode haver alguma confusão sobre qual número está fazendo a divisão e
qual está sendo dividido. Então, podemos chamá-la como uma função infixa
fazendo 92 `div` 10 e de repente fica muito mais claro.
Muitas pessoas que vêm de linguagens imperativas tendem a manter a
noção de que os parênteses devem denotar a aplicação de funções. Por
exemplo, em C, você usa parênteses para chamar funções como
foo(), bar(1) ou baz(3, "haha").
Como dissemos, espaços são usados para aplicação de funções em Haskell.
Portanto, essas funções em Haskell seriam foo,
bar 1 e baz 3 "haha". Portanto, se você vir
algo como bar (bar 3), isso não significa que
bar é chamado com bar e 3 como
parâmetros. Isso significa que primeiro chamamos a função
bar com 3 como parâmetro para obter algum
número e depois chamamos bar novamente com esse número. Em
C, isso seria algo como bar(bar(3)).
Primeiras funções do bebê
Na seção anterior, tivemos uma noção básica de como chamar funções. Agora vamos tentar fazer as nossas! Abra seu editor de texto favorito e digite esta função que pega um número e o multiplica por dois.
doubleMe x = x + xAs funções são definidas de maneira semelhante a como são chamadas. O
nome da função é seguido por parâmetros separados por espaços. Mas, ao
definir funções, há um = e depois definimos o que a função
faz. Salve isso como baby.hs ou algo assim. Agora navegue
até onde está salvo e execute o ghci a partir daí. Uma vez
dentro do GHCI, faça :l baby. Agora que nosso script está
carregado, podemos brincar com a função que definimos.
ghci> :l baby
[1 of 1] Compiling Main ( baby.hs, interpreted )
Ok, one module loaded.
ghci> doubleMe 9
18
ghci> doubleMe 8.3
16.6Como o + funciona em números inteiros e em números de
ponto flutuante (qualquer coisa que possa ser considerada um número, na
verdade), nossa função também funciona em qualquer número. Vamos fazer
uma função que pega dois números e multiplica cada um por dois e depois
os soma.
doubleUs x y = x*2 + y*2Simples. Poderíamos também ter definido como
doubleUs x y = x + x + y + y. Testá-lo produz resultados
bastante previsíveis (lembre-se de anexar essa função ao arquivo
baby.hs, salvá-lo e depois fazer :l baby
dentro do GHCI).
ghci> doubleUs 4 9
26
ghci> doubleUs 2.3 34.2
73.0
ghci> doubleUs 28 88 + doubleMe 123
478Como esperado, você pode chamar suas próprias funções de outras
funções que você criou. Com isso em mente, poderíamos redefinir
doubleUs assim:
doubleUs x y = doubleMe x + doubleMe yEste é um exemplo muito simples de um padrão comum que você verá em
Haskell. Fazer funções básicas que são obviamente corretas e combiná-las
em funções mais complexas. Dessa forma, você também evita repetições. E
se alguns matemáticos decidissem que 2 é na verdade 3 e você tivesse que
mudar seu programa? Você poderia simplesmente redefinir
doubleMe para ser x + x + x e, como
doubleUs chama doubleMe, funcionaria
automaticamente neste estranho mundo novo onde 2 é 3.
As funções em Haskell não precisam estar em nenhuma ordem específica,
portanto, não importa se você define doubleMe primeiro e
depois doubleUs ou se faz o contrário.
Agora vamos fazer uma função que multiplica um número por 2, mas apenas se esse número for menor ou igual a 100, porque números maiores que 100 já são grandes o suficiente!
doubleSmallNumber x = if x > 100
then x
else x*2
Bem aqui introduzimos a declaração if do Haskell. Você provavelmente
está familiarizado com declarações if de outras linguagens. A diferença
entre a declaração if do Haskell e as declarações if em linguagens
imperativas é que a parte else é obrigatória no Haskell. Em linguagens
imperativas, você pode pular algumas etapas se a condição não for
satisfeita, mas em Haskell toda expressão e função deve retornar algo.
Poderíamos ter escrito essa declaração if em uma linha, mas acho essa
maneira mais legível. Outra coisa sobre a declaração if em Haskell é que
ela é uma expressão. Uma expressão é basicamente um pedaço de
código que retorna um valor. 5 é uma expressão porque
retorna 5, 4 + 8 é uma expressão, x + y é uma
expressão porque retorna a soma de x e y. Como
o else é obrigatório, uma declaração if sempre retornará algo e é por
isso que é uma expressão. Se quiséssemos adicionar um a cada número
produzido em nossa função anterior, poderíamos ter escrito seu corpo
assim.
doubleSmallNumber' x = (if x > 100 then x else x*2) + 1Se tivéssemos omitido os parênteses, teria adicionado um apenas se
x não fosse maior que 100. Observe o ' no
final do nome da função. Esse apóstrofo não tem nenhum significado
especial na sintaxe do Haskell. É um caractere válido para usar em um
nome de função. Geralmente usamos ' para denotar uma versão
estrita de uma função (uma que não é preguiçosa) ou uma versão
ligeiramente modificada de uma função ou variável. Como ' é
um caractere válido em funções, podemos fazer uma função como esta.
conanO'Brien = "It's a-me, Conan O'Brien!"Há duas coisas dignas de nota aqui. A primeira é que no nome da
função não colocamos o nome de Conan em maiúscula. Isso ocorre porque as
funções não podem começar com letras maiúsculas. Veremos o porquê um
pouco mais tarde. A segunda coisa é que essa função não recebe nenhum
parâmetro. Quando uma função não recebe nenhum parâmetro, geralmente
dizemos que é uma definição (ou um nome). Como não
podemos mudar o que os nomes (e funções) significam depois de
defini-los, conanO'Brien e a string
"It's a-me, Conan O'Brien!" podem ser usados de forma
intercambiável.
Uma introdução às listas
 Assim como listas de compras
no mundo real, as listas em Haskell são muito úteis. É a estrutura de
dados mais usada e pode ser usada de várias maneiras diferentes para
modelar e resolver um monte de problemas. Listas são TÃO incríveis.
Nesta seção, veremos o básico de listas, strings (que são listas) e
compreensões de lista (list comprehensions).
Assim como listas de compras
no mundo real, as listas em Haskell são muito úteis. É a estrutura de
dados mais usada e pode ser usada de várias maneiras diferentes para
modelar e resolver um monte de problemas. Listas são TÃO incríveis.
Nesta seção, veremos o básico de listas, strings (que são listas) e
compreensões de lista (list comprehensions).
Em Haskell, as listas são uma estrutura de dados homogênea. Elas armazenam vários elementos do mesmo tipo. Isso significa que podemos ter uma lista de números inteiros ou uma lista de caracteres, mas não podemos ter uma lista que tenha alguns números inteiros e depois alguns caracteres. E agora, uma lista!
ghci> lostNumbers = [4,8,15,16,23,42]
ghci> lostNumbers
[4,8,15,16,23,42]Como você pode ver, as listas são denotadas por colchetes e os
valores nas listas são separados por vírgulas. Se tentássemos uma lista
como [1,2,'a',3,'b','c',4], Haskell reclamaria que
caracteres (que são, a propósito, denotados como um caractere entre
aspas simples) não são números. Falando em caracteres, strings são
apenas listas de caracteres. "hello" é apenas açúcar
sintático para ['h','e','l','l','o']. Como strings são
listas, podemos usar funções de lista nelas, o que é muito útil.
Uma tarefa comum é juntar duas listas. Isso é feito usando o operador
++.
ghci> [1,2,3,4] ++ [9,10,11,12]
[1,2,3,4,9,10,11,12]
ghci> "hello" ++ " " ++ "world"
"hello world"
ghci> ['w','o'] ++ ['o','t']
"woot"Cuidado ao usar repetidamente o operador ++ em strings
longas. Quando você junta duas listas (mesmo se você anexar uma lista
singleton a uma lista, por exemplo: [1,2,3] ++ [4]),
internamente, Haskell tem que percorrer toda a lista do lado esquerdo de
++. Isso não é um problema ao lidar com listas que não são
muito grandes. Mas colocar algo no final de uma lista com cinquenta
milhões de entradas vai demorar um pouco. No entanto, colocar algo no
início de uma lista usando o operador : (também chamado de
operador cons) é instantâneo.
ghci> 'A':" SMALL CAT"
"A SMALL CAT"
ghci> 5:[1,2,3,4,5]
[5,1,2,3,4,5]Observe como : recebe um número e uma lista de números
ou um caractere e uma lista de caracteres, enquanto ++
recebe duas listas. Mesmo se você estiver adicionando um elemento ao
final de uma lista com ++, deve cercá-lo com colchetes para
que se torne uma lista.
[1,2,3] é na verdade apenas açúcar sintático para
1:2:3:[]. [] é uma lista vazia. Se precedermos
3 a ela, ela se tornará [3]. Se precedermos
2 a isso, ela se tornará [2,3], e assim por
diante.
Nota: [], [[]] e
[[],[],[]] são todas coisas diferentes. O primeiro é uma
lista vazia, o segundo é uma lista que contém uma lista vazia, o
terceiro é uma lista que contém três listas vazias.
Se você quiser obter um elemento de uma lista por índice, use
!!. Os índices começam em 0.
ghci> "Steve Buscemi" !! 6
'B'
ghci> [9.4,33.2,96.2,11.2,23.25] !! 1
33.2Mas se você tentar obter o sexto elemento de uma lista que tem apenas quatro elementos, receberá um erro, então tenha cuidado!
Listas também podem conter listas. Elas também podem conter listas que contêm listas que contêm listas…
ghci> b = [[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3]]
ghci> b
[[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3]]
ghci> b ++ [[1,1,1,1]]
[[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3],[1,1,1,1]]
ghci> [6,6,6]:b
[[6,6,6],[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3]]
ghci> b !! 2
[1,2,2,3,4]As listas dentro de uma lista podem ter comprimentos diferentes, mas não podem ser de tipos diferentes. Assim como você não pode ter uma lista que tenha alguns caracteres e alguns números, você não pode ter uma lista que tenha algumas listas de caracteres e algumas listas de números.
As listas podem ser comparadas se as coisas que elas contêm puderem
ser comparadas. Ao usar <, <=,
> e >= para comparar listas, elas são
comparadas em ordem lexicográfica. Primeiro, as cabeças (heads) são
comparadas. Se forem iguais, os segundos elementos são comparados,
etc.
ghci> [3,2,1] > [2,1,0]
True
ghci> [3,2,1] > [2,10,100]
True
ghci> [3,4,2] > [3,4]
True
ghci> [3,4,2] > [2,4]
True
ghci> [3,4,2] == [3,4,2]
TrueO que mais você pode fazer com listas? Aqui estão algumas funções básicas que operam em listas.
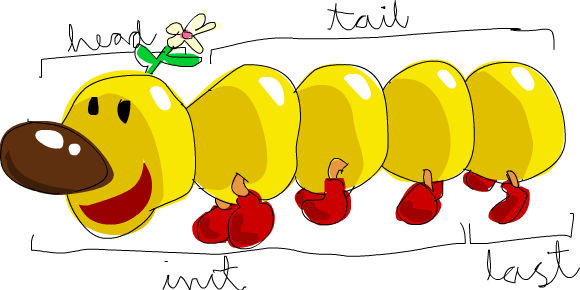
head pega uma lista e retorna sua
cabeça (head). A cabeça de uma lista é basicamente seu primeiro
elemento.
ghci> head [5,4,3,2,1]
5tail pega uma lista e retorna sua
cauda (tail). Em outras palavras, corta a cabeça de uma lista.
ghci> tail [5,4,3,2,1]
[4,3,2,1]last pega uma lista e retorna seu
último elemento.
ghci> last [5,4,3,2,1]
1init pega uma lista e retorna
tudo, exceto seu último elemento.
ghci> init [5,4,3,2,1]
[5,4,3,2]Se pensarmos em uma lista como um monstro, aqui está o que é o quê.
Mas o que acontece se tentarmos pegar a cabeça de uma lista vazia?
ghci> head []
*** Exception: Prelude.head: empty listOh céus! Tudo explode na nossa cara! Se não há monstro, ele não tem
cabeça. Ao usar head, tail, last
e init, tenha cuidado para não usá-los em listas vazias.
Esse erro não pode ser detectado em tempo de compilação, portanto, é
sempre uma boa prática tomar precauções contra dizer acidentalmente a
Haskell para fornecer alguns elementos de uma lista vazia.
length pega uma lista e retorna
seu comprimento, obviamente.
ghci> length [5,4,3,2,1]
5null verifica se uma lista está
vazia. Se estiver, retorna True, caso contrário, retorna
False. Use esta função em vez de xs == [] (se
você tiver uma lista chamada xs).
ghci> null [1,2,3]
False
ghci> null []
Truereverse inverte uma lista.
ghci> reverse [5,4,3,2,1]
[1,2,3,4,5]take pega um número e uma lista.
Ele extrai essa quantidade de elementos do início da lista. Veja.
ghci> take 3 [5,4,3,2,1]
[5,4,3]
ghci> take 1 [3,9,3]
[3]
ghci> take 5 [1,2]
[1,2]
ghci> take 0 [6,6,6]
[]Veja como, se tentarmos pegar mais elementos do que há na lista, ela apenas retorna a lista. Se tentarmos pegar 0 elementos, obtemos uma lista vazia.
drop funciona de maneira
semelhante, apenas descarta o número de elementos do início de uma
lista.
ghci> drop 3 [8,4,2,1,5,6]
[1,5,6]
ghci> drop 0 [1,2,3,4]
[1,2,3,4]
ghci> drop 100 [1,2,3,4]
[]maximum pega uma lista de coisas
que podem ser colocadas em algum tipo de ordem e retorna o maior
elemento.
minimum retorna o menor.
ghci> minimum [8,4,2,1,5,6]
1
ghci> maximum [1,9,2,3,4]
9sum pega uma lista de números e
retorna sua soma.
product pega uma lista de números
e retorna seu produto.
ghci> sum [5,2,1,6,3,2,5,7]
31
ghci> product [6,2,1,2]
24
ghci> product [1,2,5,6,7,9,2,0]
0elem pega uma coisa e uma lista
de coisas e nos diz se essa coisa é um elemento da lista. Geralmente é
chamado como uma função infixa porque é mais fácil de ler dessa
maneira.
ghci> 4 `elem` [3,4,5,6]
True
ghci> 10 `elem` [3,4,5,6]
FalseEssas foram algumas funções básicas que operam em listas. Vamos dar uma olhada em mais funções de lista mais tarde.
Intervalos do Texas (Texas ranges)
 E se quisermos uma lista de todos
os números entre 1 e 20? Claro, poderíamos digitar todos eles, mas
obviamente isso não é uma solução para cavalheiros que exigem excelência
de suas linguagens de programação. Em vez disso, usaremos intervalos
(ranges). Os intervalos são uma maneira de criar listas que são
sequências aritméticas de elementos que podem ser enumerados. Os números
podem ser enumerados. Um, dois, três, quatro, etc. Os caracteres também
podem ser enumerados. O alfabeto é uma enumeração de caracteres de A a
Z. Nomes não podem ser enumerados. O que vem depois de “John”? Eu não
sei.
E se quisermos uma lista de todos
os números entre 1 e 20? Claro, poderíamos digitar todos eles, mas
obviamente isso não é uma solução para cavalheiros que exigem excelência
de suas linguagens de programação. Em vez disso, usaremos intervalos
(ranges). Os intervalos são uma maneira de criar listas que são
sequências aritméticas de elementos que podem ser enumerados. Os números
podem ser enumerados. Um, dois, três, quatro, etc. Os caracteres também
podem ser enumerados. O alfabeto é uma enumeração de caracteres de A a
Z. Nomes não podem ser enumerados. O que vem depois de “John”? Eu não
sei.
Para fazer uma lista contendo todos os números naturais de 1 a 20,
basta escrever [1..20]. Isso é o equivalente a escrever
[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20] e não
há diferença entre escrever um ou outro, exceto que escrever longas
sequências de enumeração manualmente é estúpido.
ghci> [1..20]
[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]
ghci> ['a'..'z']
"abcdefghijklmnopqrstuvwxyz"
ghci> ['K'..'Z']
"KLMNOPQRSTUVWXYZ"Os intervalos são legais porque você também pode especificar um passo. E se quisermos todos os números pares entre 1 e 20? Ou a cada terceiro número entre 1 e 20?
ghci> [2,4..20]
[2,4,6,8,10,12,14,16,18,20]
ghci> [3,6..20]
[3,6,9,12,15,18]É simplesmente uma questão de separar os dois primeiros elementos com
uma vírgula e depois especificar qual é o limite superior. Embora
bastante inteligentes, os intervalos com passos não são tão inteligentes
quanto algumas pessoas esperam que sejam. Você não pode fazer
[1,2,4,8,16..100] e esperar obter todas as potências de 2.
Primeiro, porque você só pode especificar um passo. E segundo, porque
algumas sequências que não são aritméticas são ambíguas se dadas apenas
por alguns de seus primeiros termos.
Para fazer uma lista com todos os números de 20 a 1, você não pode
simplesmente fazer [20..1], você tem que fazer
[20,19..1].
Cuidado ao usar números de ponto flutuante em intervalos! Como eles não são completamente precisos (por definição), seu uso em intervalos pode gerar alguns resultados bastante estranhos.
ghci> [0.1, 0.3 .. 1]
[0.1,0.3,0.5,0.7,0.8999999999999999,1.0999999999999999]Meu conselho é não usá-los em intervalos de lista.
Você também pode usar intervalos para fazer listas infinitas
simplesmente não especificando um limite superior. Mais tarde,
entraremos em mais detalhes sobre listas infinitas. Por enquanto, vamos
examinar como você obteria os primeiros 24 múltiplos de 13. Claro, você
poderia fazer [13,26..24*13]. Mas há uma maneira melhor:
take 24 [13,26..]. Como Haskell é preguiçoso, ele não
tentará avaliar a lista infinita imediatamente, porque nunca terminaria.
Ele vai esperar para ver o que você quer tirar dessas listas infinitas.
E aqui ele vê que você quer apenas os primeiros 24 elementos e ele
concorda com prazer.
Um punhado de funções que produzem listas infinitas:
cycle pega uma lista e a alterna
em uma lista infinita. Se você apenas tentar exibir o resultado,
continuará para sempre, então você terá que cortá-lo em algum lugar.
ghci> take 10 (cycle [1,2,3])
[1,2,3,1,2,3,1,2,3,1]
ghci> take 12 (cycle "LOL ")
"LOL LOL LOL "repeat pega um elemento e produz
uma lista infinita apenas desse elemento. É como repetir uma lista com
apenas um elemento.
ghci> take 10 (repeat 5)
[5,5,5,5,5,5,5,5,5,5]Embora seja mais simples usar a função replicate se você quiser algum número do
mesmo elemento em uma lista. replicate 3 10 retorna
[10,10,10].
Eu sou uma compreensão de lista (list comprehension)
 Se você já fez um curso de
matemática, provavelmente já se deparou com compreensões de
conjunto. Elas são normalmente usadas para construir conjuntos mais
específicos a partir de conjuntos gerais. Uma compreensão básica para um
conjunto que contém os primeiros dez números naturais pares é
Se você já fez um curso de
matemática, provavelmente já se deparou com compreensões de
conjunto. Elas são normalmente usadas para construir conjuntos mais
específicos a partir de conjuntos gerais. Uma compreensão básica para um
conjunto que contém os primeiros dez números naturais pares é 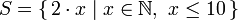 .
A parte antes do pipe é chamada de função de saída,
.
A parte antes do pipe é chamada de função de saída, x é a
variável, N é o conjunto de entrada e
x <= 10 é o predicado. Isso significa que o conjunto
contém os dobros de todos os números naturais que satisfazem o
predicado.
Se quiséssemos escrever isso em Haskell, poderíamos fazer algo como
take 10 [2,4..]. Mas e se não quiséssemos dobros dos
primeiros 10 números naturais, mas algum tipo de função mais complexa
aplicada a eles? Poderíamos usar uma compreensão de lista para isso. As
compreensões de lista são muito semelhantes às compreensões de conjunto.
Vamos nos ater a obter os primeiros 10 números pares por enquanto. A
compreensão de lista que poderíamos usar é
[x*2 | x <- [1..10]]. x é extraído de
[1..10] e para cada elemento em [1..10] (que
vinculamos a x), obtemos esse elemento, apenas dobrado.
Aqui está essa compreensão em ação.
ghci> [x*2 | x <- [1..10]]
[2,4,6,8,10,12,14,16,18,20]Como você pode ver, obtemos os resultados desejados. Agora vamos adicionar uma condição (ou um predicado) a essa compreensão. Os predicados vêm depois das partes de ligação e são separados delas por uma vírgula. Digamos que queremos apenas os elementos que, dobrados, são maiores ou iguais a 12.
ghci> [x*2 | x <- [1..10], x*2 >= 12]
[12,14,16,18,20]Legal, funciona. Que tal se quiséssemos todos os números de 50 a 100 cujo resto quando dividido pelo número 7 é 3? Fácil.
ghci> [ x | x <- [50..100], x `mod` 7 == 3]
[52,59,66,73,80,87,94]Sucesso! Observe que remover listas por predicados também é chamado
de filtragem. Pegamos uma lista de números e os
filtramos pelo predicado. Agora, outro exemplo. Digamos que queremos uma
compreensão que substitua cada número ímpar maior que 10 por
"BANG!" e cada número ímpar menor que 10 por
"BOOM!". Se um número não for ímpar, nós o jogamos fora da
nossa lista. Por conveniência, colocaremos essa compreensão dentro de
uma função para que possamos reutilizá-la facilmente.
boomBangs xs = [ if x < 10 then "BOOM!" else "BANG!" | x <- xs, odd x]A última parte da compreensão é o predicado. A função
odd retorna True em um número ímpar e
False em um par. O elemento é incluído na lista somente se
todos os predicados forem avaliados como True.
ghci> boomBangs [7..13]
["BOOM!","BOOM!","BANG!","BANG!"]Podemos incluir vários predicados. Se quiséssemos todos os números de 10 a 20 que não são 13, 15 ou 19, faríamos:
ghci> [ x | x <- [10..20], x /= 13, x /= 15, x /= 19]
[10,11,12,14,16,17,18,20]Não apenas podemos ter vários predicados em compreensões de lista (um
elemento deve satisfazer todos os predicados para ser incluído na lista
resultante), também podemos extrair de várias listas. Ao extrair de
várias listas, as compreensões produzem todas as combinações das listas
fornecidas e, em seguida, as unem pela função de saída que fornecemos.
Uma lista produzida por uma compreensão que extrai de duas listas de
comprimento 4 terá um comprimento de 16, desde que não as filtremos. Se
tivermos duas listas, [2,5,10] e [8,10,11] e
quisermos obter os produtos de todas as combinações possíveis entre
números nessas listas, eis o que faríamos.
ghci> [ x*y | x <- [2,5,10], y <- [8,10,11]]
[16,20,22,40,50,55,80,100,110]Como esperado, o comprimento da nova lista é 9. E se quiséssemos todos os produtos possíveis com mais de 50?
ghci> [ x*y | x <- [2,5,10], y <- [8,10,11], x*y > 50]
[55,80,100,110]Que tal uma compreensão de lista que combina uma lista de adjetivos e uma lista de substantivos… para uma hilaridade épica.
ghci> nouns = ["hobo","frog","pope"]
ghci> adjectives = ["lazy","grouchy","scheming"]
ghci> [adjective ++ " " ++ noun | adjective <- adjectives, noun <- nouns]
["lazy hobo","lazy frog","lazy pope","grouchy hobo","grouchy frog",
"grouchy pope","scheming hobo","scheming frog","scheming pope"]Eu sei! Vamos escrever nossa própria versão de length!
Vamos chamá-la de length'.
length' xs = sum [1 | _ <- xs]_ significa que não nos importamos com o que extrairemos
da lista de qualquer maneira; portanto, em vez de escrever um nome de
variável que nunca usaremos, apenas escrevemos _. Essa
função substitui cada elemento de uma lista por 1 e depois
soma tudo. Isso significa que a soma resultante será o comprimento da
nossa lista.
Apenas um lembrete amigável: como as strings são listas, podemos usar compreensões de lista para processar e produzir strings. Aqui está uma função que pega uma string e remove tudo, exceto letras maiúsculas.
removeNonUppercase st = [ c | c <- st, c `elem` ['A'..'Z']]Testando:
ghci> removeNonUppercase "Hahaha! Ahahaha!"
"HA"
ghci> removeNonUppercase "IdontLIKEFROGS"
"ILIKEFROGS"O predicado aqui faz todo o trabalho. Diz que o caractere será
incluído na nova lista apenas se for um elemento da lista
['A'..'Z']. Compreensões de lista aninhadas também são
possíveis se você estiver operando em listas que contêm listas. Uma
lista contém várias listas de números. Vamos remover todos os números
ímpares sem achatar a lista.
ghci> let xxs = [[1,3,5,2,3,1,2,4,5],[1,2,3,4,5,6,7,8,9],[1,2,4,2,1,6,3,1,3,2,3,6]]
ghci> [ [ x | x <- xs, even x ] | xs <- xxs]
[[2,2,4],[2,4,6,8],[2,4,2,6,2,6]]Você pode escrever compreensões de lista em várias linhas. Portanto, se você não estiver no GHCI, é melhor dividir compreensões de lista mais longas em várias linhas, especialmente se estiverem aninhadas.
Tuplas

De certa forma, as tuplas são como listas — são uma maneira de armazenar vários valores em um único valor. No entanto, existem algumas diferenças fundamentais. Uma lista de números é uma lista de números. Esse é o seu tipo e não importa se tem apenas um número ou uma quantidade infinita de números. As tuplas, no entanto, são usadas quando você sabe exatamente quantos valores deseja combinar e seu tipo depende de quantos componentes ela tem e dos tipos dos componentes. Elas são denotadas com parênteses e seus componentes são separados por vírgulas.
Outra diferença fundamental é que elas não precisam ser homogêneas. Ao contrário de uma lista, uma tupla pode conter uma combinação de vários tipos.
Pense em como representaríamos um vetor bidimensional em Haskell. Uma
maneira seria usar uma lista. Isso meio que funcionaria. E se
quiséssemos colocar alguns vetores em uma lista para representar pontos
de uma forma em um plano bidimensional? Poderíamos fazer algo como
[[1,2],[8,11],[4,5]]. O problema com esse método é que
também poderíamos fazer coisas como [[1,2],[8,11,5],[4,5]],
com o que Haskell não tem problema, pois ainda é uma lista de listas com
números, mas meio que não faz sentido. Mas uma tupla de tamanho dois
(também chamada de par) é seu próprio tipo, o que significa que uma
lista não pode ter alguns pares nela e depois um trio (uma tupla de
tamanho três), então vamos usar isso. Em vez de cercar os vetores com
colchetes, usamos parênteses: [(1,2),(8,11),(4,5)]. E se
tentássemos fazer uma forma como [(1,2),(8,11,5),(4,5)]?
Bem, teríamos este erro:
<interactive>:1:8: error: [GHC-83865]
• Couldn't match expected type: (a, b)
with actual type: (a0, b0, c0)
• In the expression: (8, 11, 5)
In the expression: [(1, 2), (8, 11, 5), (4, 5)]
In an equation for ‘it’: it = [(1, 2), (8, 11, 5), (4, 5)]
• Relevant bindings include
it :: [(a, b)] (bound at <interactive>:1:1)Ele está nos dizendo que tentamos usar um par e um trio na mesma
lista, o que não deveria acontecer. Você também não poderia fazer uma
lista como [(1,2),("One",2)] porque o primeiro elemento da
lista é um par de números e o segundo elemento é um par consistindo de
uma string e um número. As tuplas também podem ser usadas para
representar uma grande variedade de dados. Por exemplo, se quiséssemos
representar o nome e a idade de alguém em Haskell, poderíamos usar um
trio: ("Christopher", "Walken", 55). Como visto neste
exemplo, as tuplas também podem conter listas.
Use tuplas quando souber com antecedência quantos componentes algum dado deve ter. As tuplas são muito mais rígidas porque cada tamanho diferente de tupla é seu próprio tipo, então você não pode escrever uma função geral para anexar um elemento a uma tupla — você teria que escrever uma função para anexar a um par, uma função para anexar a um trio, uma função para anexar a uma 4-tupla, etc.
Embora existam listas singleton, não existe tupla singleton. Na verdade, não faz muito sentido quando você pensa sobre isso. Uma tupla singleton seria apenas o valor que ela contém e, como tal, não teria nenhum benefício para nós.
Como listas, as tuplas podem ser comparadas entre si se seus componentes puderem ser comparados. Só que você não pode comparar duas tuplas de tamanhos diferentes, enquanto pode comparar duas listas de tamanhos diferentes. Duas funções úteis que operam em pares:
fst pega um par e retorna seu
primeiro componente.
ghci> fst (8,11)
8
ghci> fst ("Wow", False)
"Wow"snd pega um par e retorna seu
segundo componente. Surpresa!
ghci> snd (8,11)
11
ghci> snd ("Wow", False)
FalseNota: essas funções operam apenas em pares. Elas não funcionarão em trios, 4-tuplas, 5-tuplas, etc. Veremos a extração de dados de tuplas de maneiras diferentes um pouco mais tarde.
Uma função legal que produz uma lista de pares: zip. Ela pega duas listas e as compacta em
uma lista unindo os elementos correspondentes em pares. É uma função
muito simples, mas tem muitos usos. É especialmente útil para quando
você deseja combinar duas listas de uma maneira ou percorrer duas listas
simultaneamente. Aqui está uma demonstração.
ghci> zip [1,2,3,4,5] [5,5,5,5,5]
[(1,5),(2,5),(3,5),(4,5),(5,5)]
ghci> zip [1 .. 5] ["one", "two", "three", "four", "five"]
[(1,"one"),(2,"two"),(3,"three"),(4,"four"),(5,"five")]Ela emparelha os elementos e produz uma nova lista. O primeiro
elemento vai com o primeiro, o segundo com o segundo, etc. Observe que,
como os pares podem ter tipos diferentes neles, o zip pode
pegar duas listas que contêm tipos diferentes e compactá-las. O que
acontece se os comprimentos das listas não corresponderem?
ghci> zip [5,3,2,6,2,7,2,5,4,6,6] ["im","a","turtle"]
[(5,"im"),(3,"a"),(2,"turtle")]A lista mais longa é simplesmente cortada para corresponder ao comprimento da mais curta. Como Haskell é preguiçoso, podemos compactar listas finitas com listas infinitas:
ghci> zip [1..] ["apple", "orange", "cherry", "mango"]
[(1,"apple"),(2,"orange"),(3,"cherry"),(4,"mango")]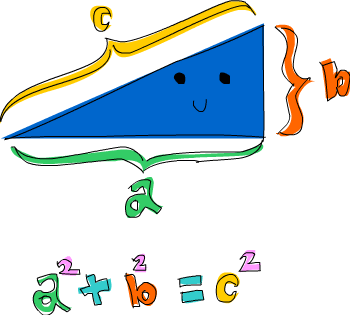
Aqui está um problema que combina tuplas e compreensões de lista: qual triângulo retângulo que tem inteiros para todos os lados e todos os lados iguais ou menores que 10 tem um perímetro de 24? Primeiro, vamos tentar gerar todos os triângulos com lados iguais ou menores a 10:
ghci> triangles = [ (a,b,c) | c <- [1..10], b <- [1..10], a <- [1..10] ]Estamos apenas extraindo de três listas e nossa função de saída as
está combinando em um trio. Se você avaliar isso digitando
triangles no GHCI, obterá uma lista de todos os triângulos
possíveis com lados menores ou iguais a 10. Em seguida, adicionaremos
uma condição de que todos eles devem ser triângulos retângulos. Também
modificaremos essa função levando em consideração que o lado b não é
maior que a hipotenusa e que o lado a não é maior que o lado b.
ghci> rightTriangles = [ (a,b,c) | c <- [1..10], b <- [1..c], a <- [1..b], a^2 + b^2 == c^2]Estamos quase terminando. Agora, apenas modificamos a função dizendo que queremos aqueles em que o perímetro é 24.
ghci> rightTriangles' = [ (a,b,c) | c <- [1..10], b <- [1..c], a <- [1..b], a^2 + b^2 == c^2, a+b+c == 24]
ghci> rightTriangles'
[(6,8,10)]E aí está a nossa resposta! Esse é um padrão comum na programação funcional. Você pega um conjunto inicial de soluções e depois aplica transformações a essas soluções e as filtra até obter as certas.